วิธีการสำหรับการ scale database
ให้รองรับข้อมูล และ traffic ที่มากขึ้นนั้น มีหลายวิธี
ยกตัวอย่างเช่น
- การขยายเครื่องให้ใหญ่ขึ้น
- การเพิ่มเรื่องให้มากขึ้น
- การจัดทำ index แต่ถ้ามีข้อมูลในแต่ละ table มากขึ้น ก็ใหญ่ ดังนั้นต้องทำ partition เพื่อให้ table เล็กลง และ index มีขนาดเล็กลง
- การทำ replication เช่น master-slave, multi-master เป็นต้น เพื่อแยกระหว่างการ read กับ write data ออกจากกัน
- การทำ house keeping ของข้อมูล ให้มีใช้และเก็บเท่าที่จำเป็น
แต่ก็ยังมีวิธีการอื่น ๆ เช่น การทำ Database Sharding
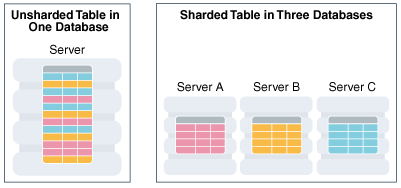
เพื่อทำการกระจายข้อมูลไปยัง database server ที่อยู่ต่างที่กัน
นั่นคือการกระจายข้อมูลไปจัดเก็บในแต่ละที่
จะช่วย share เรื่องของ data และ load ที่เข้ามาได้
แต่ความยากคือ จะแยกข้อมูลด้วยอะไร ?
เพื่อให้เกิดประโยชน์สูงสุด
โดยตรงนี้ต้องดูตาม use case ไป ว่าเป็นอย่างไรด้วย
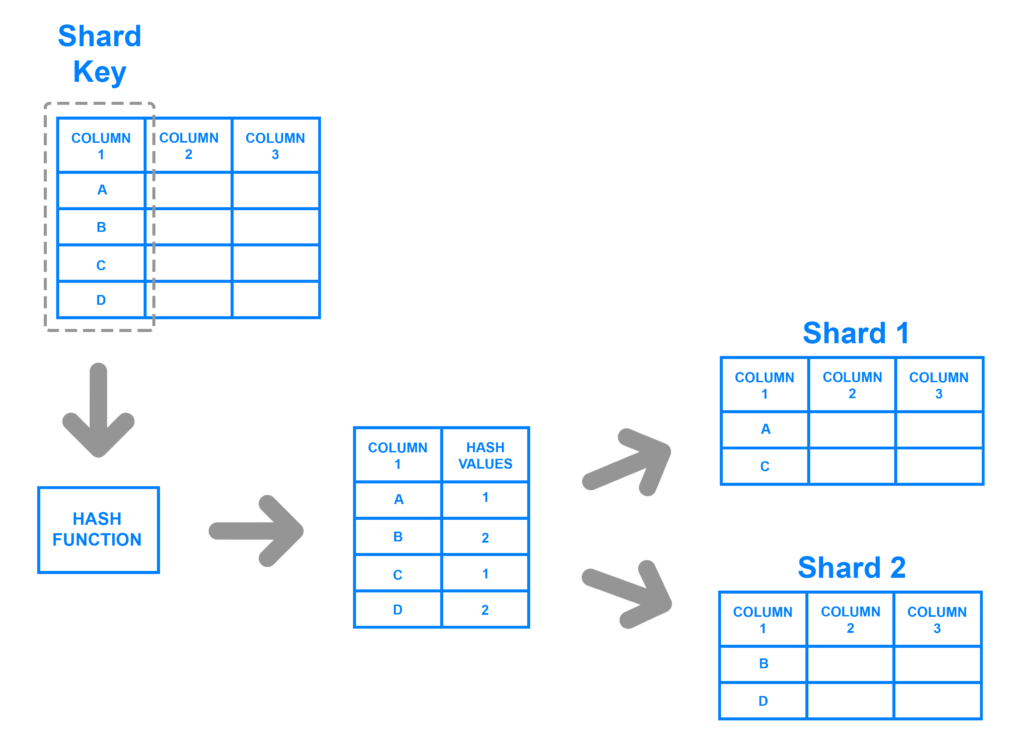
ยกตัวอย่างเช่น
- Hash-based
- Range-based
- Location-based
- Key/Directory-based
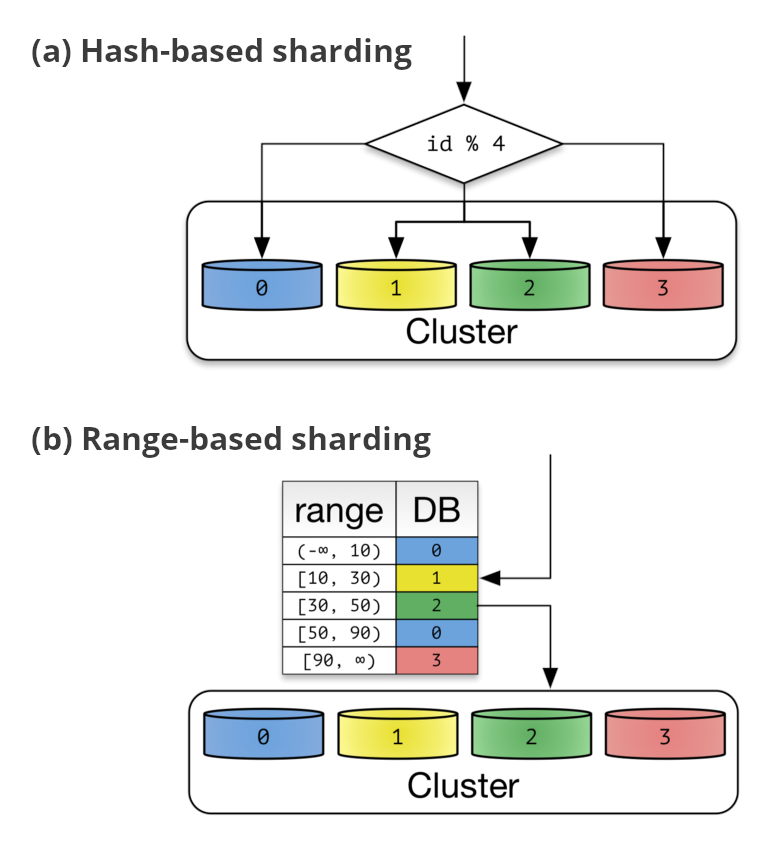
แน่นอนว่า แนวทางนี้มีทั้งข้อดีและข้อเสียเช่นกัน
ถ้าแบ่งข้อมูลผิด อาจจะทำให้ข้อมูลกระจุกอยู่ในบาง shard มากจนเกินไป
หรือในการดึงข้อมูลนั้น อาจจะต้องไปดึงจากหลาย ๆ shard ก็จะส่งผลเสียมาก ๆ
ยิ่งถ้ามีการ re-shard ก็ยิ่งใช้เวลามาก หรือ หนักกว่านั้นต้องปิดระบบเพื่อจัดการอีก
รวมไปถึงเรื่องของการ monitoring และ backup
ดังนั้นจึงมีเครื่องมือเข้ามาช่วยบ้าง
ยกตัวอย่างเช่น Vitess สำหรับ RDBMS
หรือจะเป็นพวก MonogDB และ Redis ก็มีเช่นกัน
กลับมาดูก่อนว่า ปัญหาของเราคืออะไร
แล้วจะมาดูว่า มีวิธีการอะไรช่วยแก้ไขหรือบรรเทาได้บ้าง
Reference Websites