
ในการออกแบบ architecture ของระบบงานนั้นมีรูปแบบต่าง ๆ มากมาย เช่น แต่ก็มีอีกหลายแบบที่เรียกว่า Anti-pattern architectureซึ่งผมมักจะเรียกว่า architecture ที่ไม่ดีแต่ได้รับความนิยม
ในการออกแบบ architecture ของระบบงานนั้นมีรูปแบบต่าง ๆ มากมาย เช่น แต่ก็มีอีกหลายแบบที่เรียกว่า Anti-pattern architectureซึ่งผมมักจะเรียกว่า architecture ที่ไม่ดีแต่ได้รับความนิยม
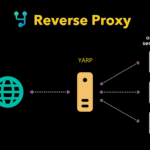
เห็นทาง Microsoft แนะนำ YARP มา สำหรับจัดการ API ต่าง ๆโดยที่ดูมานั้น เป้าหมายเพื่อสร้าง internal tool ที่ใช้งานภายในองค์กรเนื่องจากพบว่าหลาย ๆ ทีมมักจะทำงานเดียวกันซ้ำ ๆจึงสร้าง YARP ขึ้นมาซึ่งเป็น proxy นั่นเองดังนั้นมาดูกันว่าเป็นอย่างไรบ้าง

วันนี้มีโอกาสได้เข้าร่วมฟัง meetup เรื่อง MongoDB Data Modelingจากกลุ่ม MongoDB Thailand User Groupซึ่งมีหัวข้อต่าง ๆ เหล่านี้ ทำการสรุปจากสิ่งที่ได้ฟังดังนี้มาเริ่มกันเลย

ใน PostgreSQL 16 มีความสามารถใหม่ ๆ และการปรับปรุงที่เยอะเลยดังนั้นจึงทำการสรุปไว้นิดหน่อยมีทั้งความสามารถทางด้วย development และ operationมาดูกันว่ามีอะไรบ้าง

OpenTelemetry นั้นเป็น project ที่ได้รับความนิยมขึ้นมาจากเรื่องของ Distributed tracing และยังขยายเป็นเรื่อง metric กับ log ด้วยโดยที่ตัวมันเองประกอบไปด้วยส่วนการทำงานต่าง ๆ เช่น ในฝั่งของ Grafana ก็มี LGTM stackแน่นอนว่าต้องสนับสนุน OpenTelemetry อย่างแน่นอนและเพื่อให้ง่ายต่อการใช้งาน ทาง Grafana จึงได้สร้าง Docker image ออกมาในชื่อ grafana/otel-lgtmดังนั้นมาลองใช้งานกัน

บ่าย ๆ เห็นหนังสือน่าสนใจแจ้งมาทาง emailคือ Head First Software Architecture: A Learner’s Guide to Architectural Thinkingเป็นหนังสือเกี่ยวกับพื้นฐานของ Software Architecture นั่นเองเขียนมาสำหรับนักพัฒนา software ที่ต้องการเพิ่มความรู้ด้านการออกแบบและว่าง architecture ที่ดีของระบบ

จากการแบ่งปันเรื่องของ Microservices ซึ่งเป็นหนึ่งแนวทางในการแก้ไขปัญหาแต่สิ่งที่มักจะพบเจอ คือ ทำไปแล้วมีปัญหาหนักกว่าเก่าแสดงว่า อาจจะไม่ได้นำมาเพื่อแก้ไขปัญหาหรือเปล่านะเมื่อกลับมาดูที่โครงสร้างของระบบงานบ่อยครั้งจะพบปัญหามากมาย จึงทำการสรุปรูปแบบของปัญหาไว้นิดหน่อยอาจจะไม่ใช่ปัญหาก็ได้นะ
หลังจากอ่านบทความเรื่อง The Value of Socially Driven Architectureว่าด้วยเรื่องของ software architecture กับโครงสร้างขององค์กรพบว่าบ่อยครั้งที่สิ่งที่ดี ๆ จากที่อ่าน แต่เมื่อนำมาใช้งานกลับได้ดีหรือไม่ได้แก้ไข หรือ ปรับปรุงระบบให้ดีขึ้นเลยดังนั้นมาดูกันหน่อยว่าเพราะอะไร

จากการแบ่งปันเรื่อง Microservices design ที่ Skooldio มาบ้างคำถามที่น่าสนใจคือ ในทีม หรือ บริษัทนั้น มี software อะไรบ้างหรือถามลงไปในรายละเอียดเช่น ส่วนอื่น ๆ ก็เช่นกันทั้งระบบงานต่าง ๆ library ที่มี และ data pipeline ต่างๆ มีรวมไว้ตรงกลาง เพื่อให้เข้าถึง หรือ ใช้งานง่าย ๆไม่ต้องไปถามคนโน้นที คนนั้นที !!อยากให้เป็น centralize system ได้ไหมหนึ่งในเครื่องมือที่ใช้ในการจัดการสิ่งเหล่านี้ก็คือ Backstage นั่นเอง

มาดู technology stack ใหม่ที่น่าสนใจ สำหรับการพัฒนาระบบ web application ชื่อว่า AHAโดยประกอบไปด้วย