วันนี้มีโอกาสได้เข้าร่วมฟัง meetup เรื่อง MongoDB Data Modeling
จากกลุ่ม MongoDB Thailand User Group
ซึ่งมีหัวข้อต่าง ๆ เหล่านี้
- แนะนำ MongoDB ว่าเป็นอย่างไร มีเป้าหมายอะไรบ้าง ความเข้าใจผิดต่าง ๆ จากการใช้งาน
- อธิบายเรื่อง Replication และ Sharding
- แนะนำเรื่อง Data modeling pattern โดยเป็นรูปแบบตามรูปแบบการใช้งานของ application
ทำการสรุปจากสิ่งที่ได้ฟังดังนี้
มาเริ่มกันเลย
เริ่มที่แนะนำ MongoDB สักเล็กน้อย เช่น
- Flexible schema ทำให้มีความยืดหยุ่นสูง หรือ change friendly แต่ก็ต้องทำ schema validationไว้ด้วย
- No-locking column
- ง่ายต่อการดึงและวิเคราะห์ข้อมูล
- ง่ายต่อการ horizontal scale ด้วย sharing
แต่ปัญหาในการใช้งาน MongoDB คือ ความเข้าใจผิด
ก่อให้เกิดความผิดพลาดต่อการนำไปใช้งาน
หรือ แรก ๆ ระบบทำงานได้ดี แต่เมื่อเวลาผ่านไประบบช้าลงเรื่อย ๆ เป็นต้น
ยกตัวอย่างเช่น
- Normalize ข้อมูลเหมือนกับการออกแบบใน RDBMS
- ไม่ออกแบบตามการใช้งาน ทั้ง Read และ Write
- ไม่ทำการ shading ข้อมูล
ต่อมาเรื่องของ MongoDB Design
- Replication ทำการเพิ่มเครื่องเข้ามา จากนั้นทุก ๆ เครื่องก็ทำการ sync ข้อมูลไปเหมือน ๆ กัน เพื่อช่วยเพิ่มเครื่องมาช่วยงาน และช่วยเครื่อง High avaliability (HA) โดยเครื่อง prinary สำหรับ read และ write ส่วนเครื่อง secondary นั้น read-only
- Sharding ทำการกระจายข้อมูลตาม shard key ที่กำหนด เช่น hash และ range เป็นต้น หรือเรียกว่า collection sharding ไม่จำเป็นต้อง sync ข้อมูลเหมือนกันทุกเครื่อง โดย shard ยังคงมีการ replicate data อยู่นั่นเอง ใน MongoDB 7 นั้นจะมีเครื่องมือทำ sharding analytic มาให้ด้วย
การติดตั้งแบบ replication จะง่ายกว่า sharding
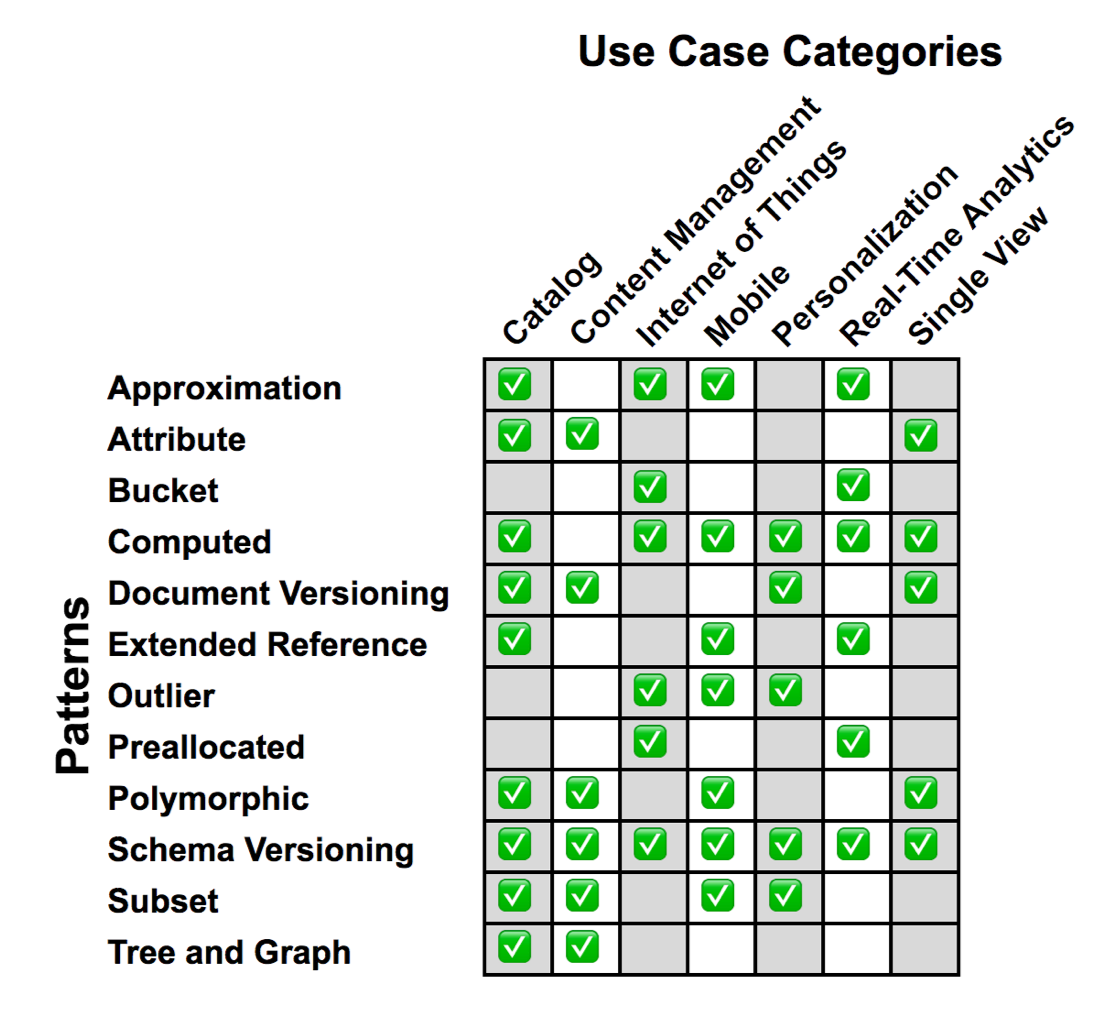
เรื่องสุดท้ายคือ Data modeling pattern สำหรับ MongoDB
โดยจะมีหลายรูปแบบมาก ๆ ขึ้นอยู่กับรูปแบบของการใช้งาน
ทั้ง read และ write
รวมทั้งยังต้องลดการ join หรือ ดึงข้อมูลหลาย ๆ ครั้ง
เนื่องจากจะถูกจัดการผ่าน application มากกว่า เช่นการ application join เป็นต้น
ซึ่งถ้าทำเยอะ ๆ ก็จะทำให้ประสิทธิภาพแย่ลง
ใน meetup ครั้งนี้ จะทำการอธิบายถึง pattern ที่ใช้งานบ่อย ๆ ดังนี้
- Computed pattern ทำการสรุปข้อมูลที่จะถูกใช้งานหรืออ่านบ่อย ๆ ไว้ก่อน เช่นการ count, summary, average หรือ grouping เป็นต้น
- Inheritance pattern หรือ Polymorphic นั่นเอง ถ้าต้องการเก็บข้อมูลที่หลากหลายใน collection เดียวกัน แล้วมีข้อมูลที่คล้าย ๆ กัน ดังนั้นทำเป็น parent/child ไปเลย ช่วยให้เก็บง่าย ดึงง่าย เช่น single view app, content management เป็นต้น
- Extended pattern ถ้าต้องใช้ข้อมูลจากหลาย ๆ collection มักต้องทำการ join ดังนั้นทำการเพิ่มข้อมูลที่ต้องการใช้ใน document ของ colelction หลักไปเลย เอาเท่าที่ใช้มานะ เพื่อลดการ join ทำให้เร็วต่อการอ่าน แต่ระวังเรื่องขนาดของ document ต้องไม่เกิน 16 MB
- Schema versioning pattern สำหรับจัดการ version ของ document ด้วยการเพิ่ม property version เข้ามา ทำให้ฝั่ง application จัดการกับข้อมูลตาม version ได้ง่าย ลด downtime ลงไป อาจจะเป็น zero-downtime ได้ อย่าลืมทำ schema validate ไว้ด้วย
- Subset pattern คล้ายกับการ extened แต่ว่าด้วยเรื่องของขนาดข้อมูลที่อาจจะใหญ่เกินไป ดังนั้นจึงให้เก็บเท่าที่จะใช้งานก่อน เช่นถ้าเป็น paging ก็เก็บ page แรกไว้ หรือ top 100 เป็นต้น
- Bucket pattern เป็น pattern ที่คิดออกมาสำหรับจัดการข้อมูลแบบ time-series, real-time analytic และ IoT เป็นต้น ทั้งการอ่านและเขียนข้อมูลปริมาณมาก ๆ เนื่องจาก disk และ memory มีจำกัด เป็นการนำเอาแนวคิดของ computed และ subset มาใช้งาน โดยใน MongoDB 5.0 ได้สร้าง Time-series collection ออกมา เพื่อให้ใช้งานง่ายขึ้น
สามารถดู pattern อื่น ๆ เพิ่มได้ที่ Building with Patterns: A Summary
Reference Websites
- Slide ของ meetup ครั้งที่ Download ได้เลย
- MongoDB Data Encryption
- Practical MongoDB Aggregations Book