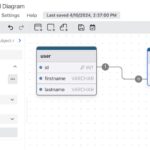
เห็นเครื่องมือชื่อว่า DrawDBเป็น editor สำหรับออกแบบ database นั่นเองสามารถใช้งานผ่านระบบ web application ได้เลยมี user interface ที่ใช้งานง่ายดี และ ฟรีด้วยสามารถนำมาติดตั้งที่ server ของเราได้เองเลย
เห็นเครื่องมือชื่อว่า DrawDBเป็น editor สำหรับออกแบบ database นั่นเองสามารถใช้งานผ่านระบบ web application ได้เลยมี user interface ที่ใช้งานง่ายดี และ ฟรีด้วยสามารถนำมาติดตั้งที่ server ของเราได้เองเลย

คำถามเกี่ยวกับการสร้าง data ใน PostgreSQL database จำนวนเยอะ ๆ ในแต่ละ table อย่างไรดี ? คำตอบง่าย ๆ สามารถใช้งานเขียน code และใช้งาน fake library ได้เลยแต่ถ้าต้องการเขียนคำสั่ง SQL ทำเลยก็สามารถทำได้ด้วยการใช้งาน GENERATE_SERIES ของ PostgreSQL นั่นเองหรือเขียนด้วย pgSQL ก็ได้ แล้วแต่ความชอบ

ใน PostgreSQL 16 มีความสามารถใหม่ ๆ และการปรับปรุงที่เยอะเลยดังนั้นจึงทำการสรุปไว้นิดหน่อยมีทั้งความสามารถทางด้วย development และ operationมาดูกันว่ามีอะไรบ้าง
ทาง Deno KV ได้ปล่อย npm สำหรับการใช้งานผ่าน NodeJS มาแล้วโดยที่ Deno KV นั้นเป็น serverless databaseมีความสามารถหลัก ๆ ดังนี้ แต่ยังอยู่ใน beta version นะครับ !!

จากการแบ่งปันการพัฒนา RESTful API ด้วยภาษา Goมีคำถามว่า ในการจัดการข้อมูลใน database ควรใช้อะไรดี ?จะใช้งาน ORM หรือ Native SQL ดี ?จึงทำการสรุปคำตอบไว้นิดหน่อย
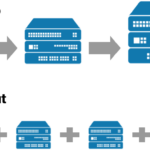
เห็นใน feed มีการ share บทความเรื่อง How Quora scaled MySQL to 100k+ Queries Per Secondเป็นการ scale MySQL database ของระบบ Quoraซึ่งเป็นระบบถามตอบปัญหาต่าง ๆ นั่นเองโดยมีการใช้งานคร่าว ๆ คือ ข้อมูลต่าง ๆ จะเก็บไว้ใน MySQL นั่นเองดังนั้นมาดูกันว่าทางระบบทำการ scale กันอย่างไร
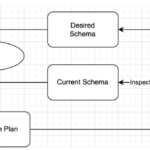
เห็นใน feed มีการ share เครื่องมือในการทำ Database migration ชื่อว่า Atlasสิ่งที่น่าสนใจคือ มีรูปแบบการทำงาน 2 แบบ คือ
พอดีต้องทำงานกับ Vector Database ทั้งPinecone, Milvus, Redis, Elasticsearch และ pgvectorเกิดคำถามว่าคืออะไร ทำงานอะไรได้บ้างเนื่องจากปกติ NoSQL จะรู้จักแค่ key-value, column, document และ graphพอมาเจอ Vector ก็เลยงง ๆดังนั้นทำความรู้จักกันหน่อย

เห็นว่ามีการ share บทความเรื่อง HOW DISCORD STORES TRILLIONS OF MESSAGES ? ซึ่งเป็นบันทึกการเปลี่ยนแปลง database ที่ใช้เก็บข้อมูลที่พูดคุยต่าง ๆ ในระบบ Discordจาก MongoDB -> Cassandra -> ScyllaDBทำให้เราเห็น use case และ เหตุผลในการเปลี่ยนแปลงนั่นคือการแก้ไขปัญหานั่นเองจึงทำการสรุปสิ่งที่สนใจเอาไว้ดังนี้

มี project ต้องการใช้งาน DBML (Database Markup Language)สำหรับการออกแบบและพัฒนาระบบงานจึงทำการสรุป flow การทำงานไว้นิดหน่อย