เห็นใน feed มีการ share บทความเรื่อง How Quora scaled MySQL to 100k+ Queries Per Secondเป็นการ scale MySQL database ของระบบ Quoraซึ่งเป็นระบบถามตอบปัญหาต่าง ๆ นั่นเองโดยมีการใช้งานคร่าว ๆ คือ ข้อมูลต่าง ๆ จะเก็บไว้ใน MySQL นั่นเองดังนั้นมาดูกันว่าทางระบบทำการ scale กันอย่างไร
Read More…
ในการแบ่งปันเรื่อง Microservices Design ที่ Skooldio นั้นมีการถามตอบเรื่องของระบบที่พัฒนาด้วย NodeJSซึ่งโดยปกติจะทำการแบบ single thread, non-blocking I/Oทำงานได้ดีอยู่แล้ว แต่เมื่อเจอ concurrent สูง ๆ ขึ้นมากลับทำงานได้ไม่ดีเลย ยิ่งลองไปเทียบกับ Go แล้ว คนละเรื่องกันเลย
Read More…
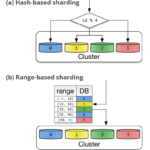
วิธีการสำหรับการ scale database ให้รองรับข้อมูล และ traffic ที่มากขึ้นนั้น มีหลายวิธียกตัวอย่างเช่น การขยายเครื่องให้ใหญ่ขึ้น การเพิ่มเรื่องให้มากขึ้น การจัดทำ index แต่ถ้ามีข้อมูลในแต่ละ table มากขึ้น ก็ใหญ่ ดังนั้นต้องทำ partition เพื่อให้ table เล็กลง และ index มีขนาดเล็กลง การทำ replication เช่น master-slave, multi-master เป็นต้น เพื่อแยกระหว่างการ read กับ write data ออกจากกัน การทำ house keeping ของข้อมูล ให้มีใช้และเก็บเท่าที่จำเป็น
Read More…
อ่านบทความเรื่อง Best practices can slow your application down จากทาง Stack Overflow โดยได้อธิบายว่า ไม่ค่อยทำตาม best practice ในการพัฒนาระบบมาเลยทั้งการออกแบบ เขียน code ที่ช่วยให้อ่านและดูแลได้ง่ายรวมถึงการทดสอบ และ deploy ระบบเป็นเรื่องที่น่าสนใจมาก ๆ ว่า แล้วตัดสินใจกันอย่างไร ?ว่าจะเลือกไปทางไหนในการพัฒนาระบบ
Read More…
เห็นใน feed มาการ share บทความเรื่อง How to design a system to scale to your first 100 million users ?มีรายละเอียดเยอะมาก ๆ หนึ่งในเรื่องที่สนใจคือ การ scaling database (RDBMS)เนื่องจากยังคงเป็นที่นิยมในการใช้งาน
Read More…
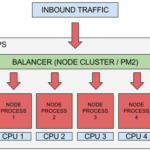
เมื่อระบบงานมีจำนวนการใช้งานที่สูงขึ้น (Work load) แล้วปัญหาที่มักจะตามมาเช่น ระบบไม่สามารถรองรับได้ หรือ scale ได้ทันความต้องการ ระบบทำงานช้า ระบบล่ม มาดูกันว่า ต้นเหตุของปัญหามีอะไรบ้าง
Read More…
ในเรื่องของการ scale ระบบนั้น ถือเป็นเรื่องสำคัญ โดยระบบที่ deploy ด้วย Kubernetes นั้น สามารถจัดการแบบง่าย ๆ ด้วย Deployment และ ReplicaSet แต่ก็ยังคงต้องทำแบบ manual ดังนั้น Kubernetes จึงได้สร้าง Horizontal Pod Autoscaler (HPA) ขึ้นมา เพื่อช่วยให้การ scale ในระดับ Pod แบบอัตโนมัติได้ โดยค่า default นั้นจะดูค่าจากการใช้งาน resource เช่น CPU เป็นต้น รวมทั้งยังใช้งานยากพอสมควร ถ้าสามารถทำการ custom ได้ รวมทั้งทำงานร่วมกับ metric อื่น ๆ ได้ น่าจะดีและมีประโยชน์กว่านั่นจึงเป็นที่มาของ Kubernetes Event Driven Autoscaling (KEDA)
Read More…