อ่านบทความเรื่อง Scaling Unsplash with a small team
อธิบายว่าทีมพัฒนาระบบ Unsplash นั้นเป็นอย่างไร
ทำงานและคิดกันอย่างไร ซึ่งเป็นอีกมุมมองที่น่าสนใจดี
จึงทำการสรุปไว้
ระบบUnsplash รองรับจำนวนการใช้งานประมาณนี้
- เรียกใช้งาน API กว่า 10 ล้าน request ต่อวัน
- มีการ process event ต่าง ๆ มากกว่า 60 ล้านครั้ง
- ให้บริการรูปภาพกว่า 60 ล้านรูป
ทีมพัฒนานั้นมีขนาดเล็กมาก ๆ ประกอบไปด้วย
- Designer 2 คน
- Fronend 3 คน พัฒนาด้วย React + Webpack และ Express สำหรับทำ Server-sider rendering และ proxy ไปยัง API
- Backend 3 คน พัฒนาด้วย Rails
- Data engineer 1 คน
เขียน test ในทุกสิ่งทุกอย่างที่ต้องการหรืออยากรู้
หน้าที่หลักของแต่ละคนคือ
การสร้างและทดลองสิ่งใหม่ ๆ
ทั้งการพัฒนาระบบและ feature ใหม่ ๆ
เพื่อทำให้ทำงานได้ดี และระบบโตไปพร้อม ๆ กัน
กว่า 3 ปีที่ทีมพัฒนาทำการปรับปรุงและทดลองสิ่งใหม่ ๆ
จนได้ principle ที่น่าจะตอบโจทย์ของทีมและบริษัท
ประกอบไปด้วย
1. Build boring, obvious solutions
ก่อนที่จะนำเครื่องมือใหม่ ๆ มาใช้
ก่อนที่จะนำ database ใหม่ ๆ มาใช้
ก่อนที่จะนำ pattern ใหม่ ๆ มาใช้
ก่อนที่จะนำ architecture ใหม่ ๆ มาใช้
คุณทำการปรับปรุงหรือแก้ไขปัญหาต่าง ๆ ดีแล้วหรือยัง ?
ยกตัวอย่างเช่นฝั่ง Backend
มักจะมีปัญหากับการใช้เครื่องมือพื้นฐานต่าง ๆ
ทำให้ระบบทำงานได้ไม่ดีอย่างที่ต้องการ
แต่ก็พยายามแก้ไขด้วยการทำ caching, batching
รวมไปถึงการทำงานแบบ asynchronous
เพื่อทำให้ระบบทำงานได้ดียิ่งขึ้น
2. Focus on solving user problems, not technology problems
ที่บริษัท Unsplash นั้นคือ product company ไม่ใช่ technology company
ดังนั้นเงินลงทุนต่าง ๆ จะมีเป้าหมายไปที่
การแก้ไขปัญหาของ product และ marketing เป็นหลัก
ว่าผู้ใช้งานมีปัญหาอะไร ก็แก้ไขตามนั้น
ดังนั้นการเลือกใช้เทคโนโลยีต่าง ๆ จึงเป็นสิ่งที่สร้างมาและใช้งานได้อยู่แล้ว
เพียงนำสิ่งเหล่านั้นมาเชื่อมต่อหรือทำงานร่วมกัน
เพื่อแก้ไขปัญหาของผู้ใช้งาน และให้ขยาย community ระบบให้ใหญ่ขึ้น
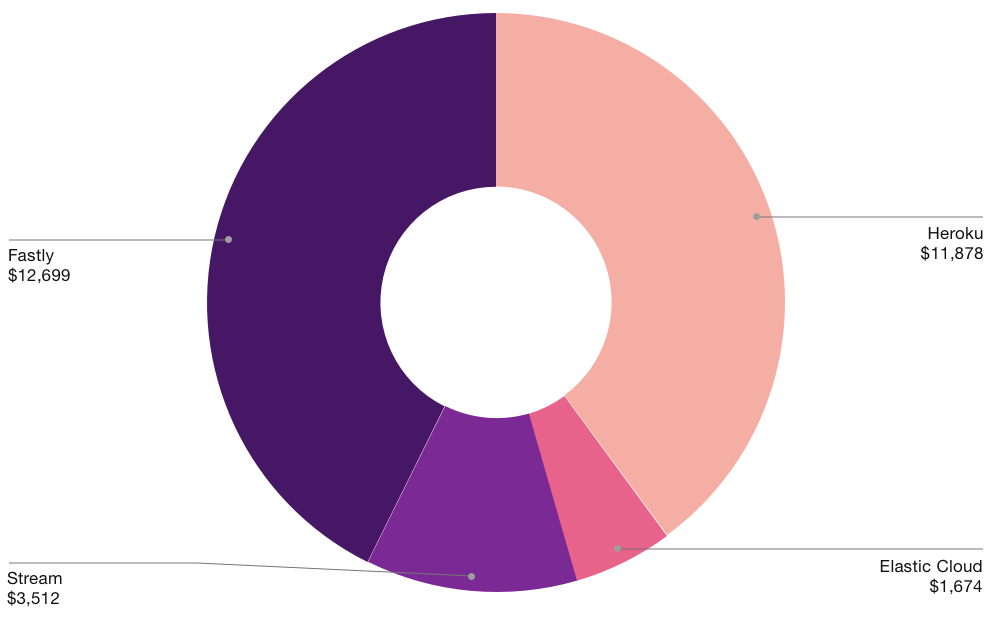
ดังนั้นจะเห็นว่าระบบของ Unsplash จะใช้ 3-party service เยอะมาก ๆ
เพื่อใช้จัดการปัญหาและงานต่าง ๆ เช่น
- Web Server ก็ใช้งาน Heroku
- CDN caching ก็ใช้ Fastly
- Elasticsearch cluster ก็ใช้ Elastic cloud
- เรื่องของ feed data และnotification ก็ใช้ Steam
- รูปต่าง ๆ ก็ไปเก็บที่ Imgix
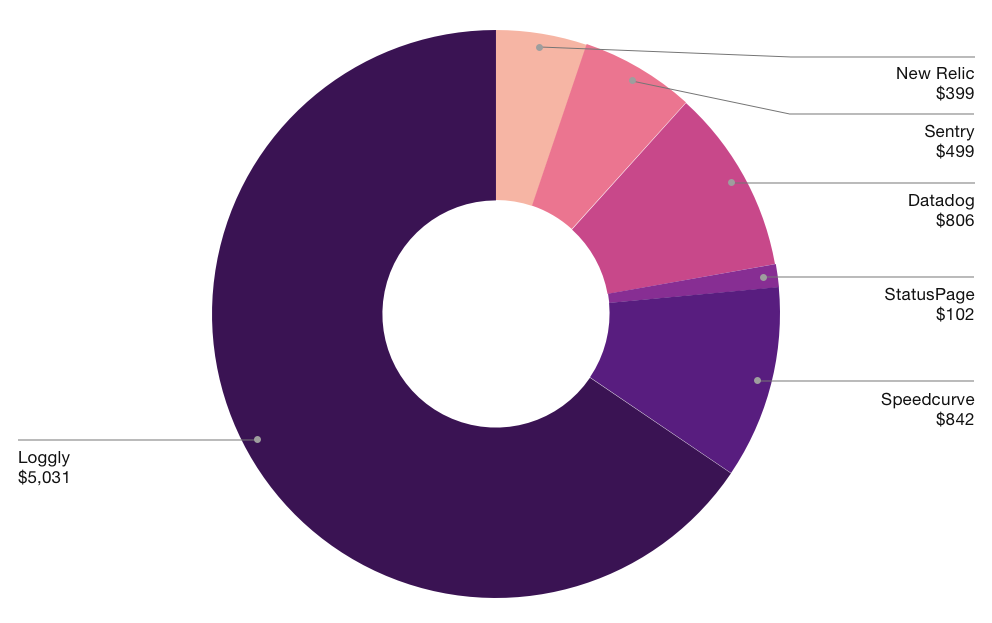
ส่วนของ Monitoring system ก็ใช้
- Centralize logging ใช้ Loggly
- Metric และค่าต่าง ๆ ของระบบ ใช้ New Relic
- Exception และ error ต่าง ๆ ใช้ Sentry, StatusPage
3. Throw money at technical problems
ง่าย ๆ คือ ใช้เงินแก้ไขปัญหา technical ไปเลย
โดยจะจ่าย service ต่าง ๆ ที่ใช้งานแบบ premium ไปเลย
เหมือนจะเป็นเครื่องที่ตลก แต่มันเป็นจริงมาก ๆ
เพราะว่า แก้ไขปัญหาที่เกิดซ้ำแล้วซ้ำเล่าทาง technical ได้ดีมาก ๆ
ส่งผลทำให้ทีมพัฒนาไป focus กับงานหรือปัญหาจากผู้ใช้งานได้เต็ม ๆ
ทำให้ระบบโตขึ้นสูงมาก ๆ
ส่วนการ optimize ค่าใช้จ่ายต่าง ๆ
ก็เป็นอีกปัญหาหนึ่งที่ต้องทำและแก้ไข เช่นกัน แต่ใครจะสนใจละ !!
Reference Websites