พอดีได้พูดคุยเกี่ยวกับการจัดการข้อมูลที่เรียกได้ว่าเป็น Big Data
ซึ่งปัญหาแรกๆ ที่คุยกันเลยก็คือ เราจะจัดเก็บข้อมูลแบบนี้ด้วยอะไรดี
แต่ก่อนอื่นนั้น สิ่งที่เราควรทำความรู้จักก่อนคือ ไอ้ Big Data เนี่ยมันคืออะไร
และมี Model การจัดการอย่างไรรวมทั้งมีเครื่องมืออะไรให้ใช้บ้าง
จึงจะทำให้เรารู้และเข้าใจ เพื่อเลือกใช้งานสิ่งที่เหมาะสมกับงานของเราจริงๆ
ก่อนอื่นมาทำความรู้จักกับ Big Data แบบคร่าวๆ
มันถูกกำหนดขึ้นมาจาก Gartner ซึ่งบอกไว้ว่า
- Big Data คือ technique และ technology สำหรับการสะกัดหรือดึงคุณค่าต่างๆ ออกมาจากข้อมูลขนาดมหาศาลได้
- Big Data คือ คำที่เอาไว้อธิบายรูปแบบการจัดการ ประมวลผลข้อมูล ซึ่งเกินข้อจำกัดของวิธีการแบบเดิมๆ
- Big Data ต้องการวิธีการขยายในแนวนอนหรือออกด้านข้าง ( Horizontal ) แบบรวดเร็ว ซึ่งวิธีการแบบเดิมๆ ไม่สามารถรองรับได้
โดยที่ Big Data ไม่ได้อยู่เพียงในวงจำกัด แค่ Facebook, Twitter, Google เท่านั้น
เนื่องจากถ้าไปดูแนวโน้มการค้นหาคำว่า Big Data
แล้วจะพบว่ามีอัตราการเติบโตที่คุณจะพลาดไม่ได้เลย ดังรูป
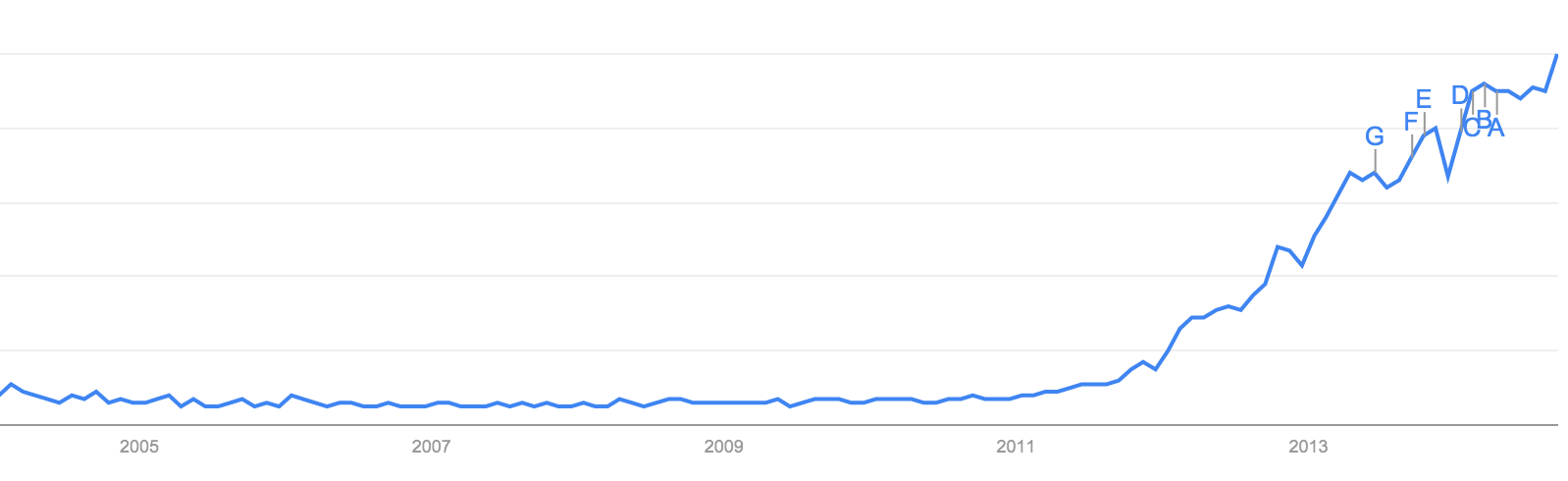
ทำความเข้าใจกับความต้องการและรูปแบบการใช้งานที่เพิ่มขึ้นของ Big Data
โดยทาง Gartner ได้กำหนดขึ้นมาเรียกว่า 3V ประกอบไปด้วย
- Volume
- Velocity
- Variety
อธิบายรวมๆ แล้ว มันก็คือ ข้อมูลที่มีขนาดใหญ่ในระดับ Terabyte กันเลยทีเดียว
แน่นอนว่าข้อมูลมันเกิดขึ้นมารวดเร็วมากๆ
สุดท้ายรูปแบบของข้อมูลจะแตกต่างกัน
ทำให้ไม่สามารถจัดเก็บลงฐานข้อมูลแบบเชิงความสัมพันธ์ได้ หรือถ้าจะทำก็ยากและซับซ้อน
จากปัญหานี้
ทำให้ผู้นำทางเทคโนโลยีพยายามหาวิธีการเพื่อแก้ไขปัญหา
สำหรับรองรับการขยายตัวของข้อมูลที่รวดเร็ว ในระบบต่างๆ เช่น
Social Network, Analytic, Game, Financial และ Medical เป็นต้น
แน่นอนว่า ถ้าเราพูดถึงการเรื่องการรองรับการขยายของฐานข้อมูล (Scaling)
จะพูดถึงการขยายในแนวนอน (Horizontal) มากกว่าแนวตั้ง (Vertical)
นั่นคือ การที่เราจะมี server หลายๆ ตัวทำงานร่วมกัน มากกว่าการขยายความสามารถของ server ให้สูงขึ้น
ดังนั้นแนวคิดเรื่อง The CAP Theorem จึงเข้ามามีบทบาทสำคัญในโลกการประมวลผลแบบกระจายหรือข้ามหลายๆ เครื่อง
โดย CAP Theorem ประกอบไปด้วย
- Consistency
- Availability
- Partitioning
ซึ่งอ่านเพิ่มเติมได้ที่กระทู้ใน Narisa.com ได้เลย อธิบายและพูดคุยกันได้ดี
ต่อไปมาดูว่า Database Model ที่มักถูกนำมาใช้จัดการข้อมูล
ว่ามี model อะไรบ้าง
แต่ละ model มีข้อดีอย่างไร
แล้วจัดการเรื่อง CAP Theorem อย่างไรกัน
1. Relational Database
ทำการเก็บข้อมูลในรูปแบบของ row และ column ดังนั้นสามารถเชื่อมโยงข้อมูลกันได้
ซึ่งข้อมูลที่ถูกจัดเก็บจะมีโครงสร้างชัดเจน รู้ว่าต้องจัดการข้อมูลในรูปแบบไหนอยู่ก่อนแล้ว
มันคือระบบ RDBMS (Relational Database Management System) หรือ ฐานข้อมูลเชิงความสัมพันธ์
โดยรูปแบบนี้เหมาะแก่การเริ่มต้นอย่างมาก เชื่อว่าทุกๆ ต้องใช้งานกัน
เรื่องการขยายระบบมักนิยมจะทำในแนวตั้ง(Vertical) มากกว่า นั้นคือการขยายเครื่องให้ใหญ่ขึ้น
แต่ถ้าต้องทำการขยายในแนวนอน(Horizontal) จะใช้วิธีการที่เรียกว่า replication
ถ้าพูดถึง CAP Theorem แล้วจะเน้นเรื่อง Consistency มากกว่า Availability
ตัวอย่าง product ในกลุ่มนี้ เช่น Oracle, MySQL, PostgreSQL, SQLite เป็นต้น
2. Document-Oriented Database
ทำการเก็บข้อมูลในรูปแบบของเอกสาร (Document)
โดยข้อมูลที่เชื่อมโยงกันจะอยู่ในเอกสารเดียวกัน ไม่มีการ join ข้อมูลเหมือนใน Relational Database
ในการขยายระบบมักจะใช้วิธีการ replication และ shading
และมักจะสนับสนุน Map/Reduce เพื่อปรับปรุงประสิทธิภาพในการดึงข้อมูล
ถ้าพูดถึง CAP Theorem แล้วจะเน้นเรื่อง Consistency มากกว่า Availability
ตัวอย่าง product ในกลุ่มนี้ เช่น MongoDB, CouchDB และ Cloudant เป็นต้น
3. Key-Value Store
ทำการเก็บข้อมูลอยู่ในรูปแบบ key-value หรือ Map นั่นเอง
รูปแบบการใช้งานจะผ่านคำสั่งง่ายๆ เพื่อให้ได้ข้อมูลที่ต้องการ
โดยในการดึงข้อมูลอาจจะมีการดึงหลายๆ ครั้ง เนื่องจากการทำงานแบบนี้
จะมีความเร็วในการทำงานสูงมากๆ ทั้งอ่านและเขียนข้อมูล
ถูกใช้มากสำหรับเก็บข้อมูลชั่วคราว (Caching) และระบบที่ต้องทำงานแบบ Realtime
ในการขยายระบบมักจะใช้วิธีการ shading ข้อมูล
ถ้าพูดถึง CAP Theorem แล้วจะเน้นเรื่อง Consistency มากกว่า Availability
ตัวอย่าง product ในกลุ่มนี้ เช่น Redis, LevelDB, CouchBase และ PostgreSQL HStore เป็นต้น
4. BigTable-Insprired Database
ทำการเก็บข้อมูลที่อยู่ในรูปแบบของ column-oriented ได้รับแรงบันดาลใจมาจาก Google BigTable
สามารถปรับค่าต่างๆ ให้สนับสนุนตาม CAP Theorm ได้เลย ว่าต้องการเน้นเรื่องอะไร
จะถูกนำมาใช้เมื่อต้องการเรื่องความถูกต้องของข้อมูล และต้องการการเขียนข้อมูลในปริมาณที่สูงมากๆ
จนรูปแบบการเก็บข้อมูลแบบเดิมๆ ไม่สามารถรองรับได้
เช่น HBase นั้นสามารถขยายด้วยการเพิ่มจำนวน node ถึง 1,000 node กันเลยทีเดียว
ถ้าพูดถึง CAP Theorem แล้วจะเน้นเรื่อง Consistency มากกว่า Availability
ตัวอย่าง product เช่น HBase และ Cassandra เป็นต้น
5. Dynamo-Insprired Database
ทำเก็บข้อมูลแบบ Distributed Key-Value ซึ่งได้รับแนงบันดาลใจมาจาก Amazon Dynamo
สิ่งที่มันแตกต่างจาก Key-Value Store ก็คือ key มันจะถูกเก็บแบบกระจายตามแต่ละ node ที่อยู่ในรูปแบบ dynamo ring
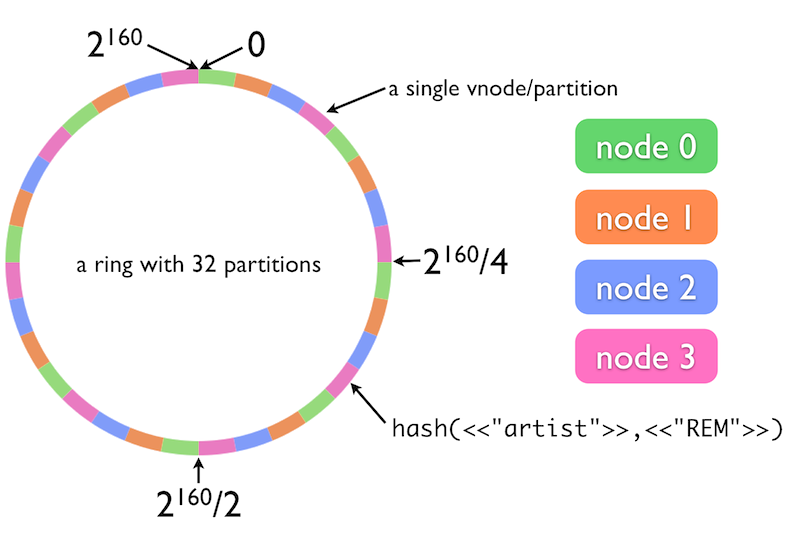
ในการขยายระบบนั้นสามารถทำได้ง่ายที่สุด และข้อมูลที่ถูกจัดเก็บมีความคงทนสูงมากๆ
ระบบที่เก็บข้อมูลในรูปแบบนี้มักจะต้องการประสิทธิภาพการเขียนที่สูงมาก
และข้อมูลเหล่านั้นมีความสำคัญ จะเสียหายไม่ได้อีกด้วย
ถ้าพูดถึง CAP Theorem แล้วจะเน้นเรื่อง Availability มากกว่า Consistency
ตัวอย่าง product เช่น Cassandra และ Riak เป็นต้น
โดยสรุปแล้ว
เราได้เห็นแล้วว่าแต่ละ Database model นั้นมีข้อดีและข้อด้อยอะไรบ้าง
โดย product ที่เลือกมาในแต่ละกลุ่มล้วนมีขนาดของ community ที่ใหญ่พอสมควร
สามารถหาข้อมูล ตัวอย่าง และ how-to ต่างๆ ได้ไม่ยากนัก
ดังนั้นถ้า database ที่คุณใช้อยู่นั้นเกิดเป็นปัญหาคอขวดของระบบงานขึ้นมา
เช่นไม่สามารถรองรับข้อมูลตามรูปแบบ 3V นั่นคือ Volumn, Veilocity และ Vareity ได้
นั่นแสดงว่า ถึงเวลาที่คุณต้องตามหา Big Data เพื่อมาแก้ไขปัญหาล่ะนะ
โดยเลือกให้เหมาะกับงานและข้อมูลของคุณครับ