
หลังจากที่ใน part 1 นั้นได้ทำการสรุปเรื่องของ Messaging system จากการไปเรียนมา
มาใน blog นี้จะทำการสรุปเกี่ยวกับความรู้พื้นฐานของ Kafka
ว่ามีที่มาที่ไปอย่างไร ?
ว่ามี architecture อย่างไร ?
ว่าการทำงานในแต่ละส่วนมีอะไร ที่ทำหน้าที่อะไร ?
รวมไปถึง ecosystem ของ Kafka ว่าเป็นอย่างไร ?
ไปดูกันเลย
จุดเริ่มต้นของ Kafka
เป็นระบบที่พัฒนาใช้ภายในบริษัท LinkedIn
เพื่อใช้จะเก็บข้อมูล metric ต่าง ๆ ของระบบ
เช่นเก็บข้อมูลการใช้งานระบบของผู้ใช้งานแต่ละคน
ซึ่งระบบดั้งเดิมจะเก็บเป็นไฟล์ XML จากนั้นเอามา parser ต่อ
แต่ทีมงานเห็นว่า ไม่น่ารอดในอนาคตอันใกล้ รวมทั้งเกิดปัญหามากมาย
ทำให้ตัดสินใจสร้างระบบใหม่ที่ชื่อว่า Kafka ออกมานั่นเอง
โดยที่ Kafka สร้างมาเพื่อ
ทำงานแบบกระจาย ไม่ต้องฝืน (Distributed system)
เป็นระบบที่คงทนต่อความเสียหาย นั่นคือทำงานได้แม้ระบบบางส่วนจะเสียหาย
มีการทำงานแบบ Publish-Subscribe
ทำการบันทึกหรือจัดการข้อมูลต่าง ๆ ใน Topic เทียบได้กับ Table ใน RDBMS
ผู้สร้างข้อมูลและส่งไปยัง topic เรียกว่า Producer
ผู้นำข้อมูลไปใช้งานจาก topic เรียกว่า Consumer
ข้อมูลที่ส่งเข้าไปใน topic จะถูกจัดเก็บแบบถาวรลง file system เสมอ
ข้อมูลที่ถูกจัดเก็บจะมีอายุ 168 ชั่วโมง ซึ่งสามารถแก้ไขได้ตาม use case
Kafka จะทำการบันทึกข้อมูลลงไฟล์หรือ log
ก่อนที่ consumer จะเห็นเพื่อนำไปทำงานหรือ process ต่อไป
ซึ่งจะเรียกระบบนี้ว่า WAL (Write-Ahead Logging)
เป้าหมายหลักของ Kafka ประกอบไปด้วย
- เพื่อไม่ให้ Producer และ Consumer ผูกมัดกัน
- ทำการการจัดเก็บข้อมูลแบบถาวร เพื่อให้ Consumer มีทางเลือกมากขึ้น นั่นคือสนับสนุนรูปแบบการทำงานที่หลากหลาย รวมทั้งง่ายต่อการจัดการเมื่อเกิดข้อผิดพลาดขึ้นมา
- มีการทำงานที่รวดเร็ว นั่นคือสามารถรองรับข้อมูลที่เกิดมาอย่างรวดเร็วได้ดี เช่น user activity และ logging หรือเกิดมาเพื่อรองรับ Stream Processing Architecture นั่นเอง
- สามารถ scale ได้ง่าย
มาดูสถาปัตยกรรมของ Kafka กันบ้าง
จากที่อธิบายมานั้น Kafka จะมี Producer, Consumer และ Topic
โดยที่ในแต่ละ topic นั้นจะแบ่งการเก็บข้อมูลออกเป็นกลุ่ม ๆ เรียกว่า Partition
จำนวนของ partition จะต้องถูกกำหนดไว้ตั้งแต่ต้น
(ไม่ควรเปลี่ยนเมื่อระบบทำงานแล้ว เพราะว่า operation เยอะมาก ๆ)
แสดงดังรูป
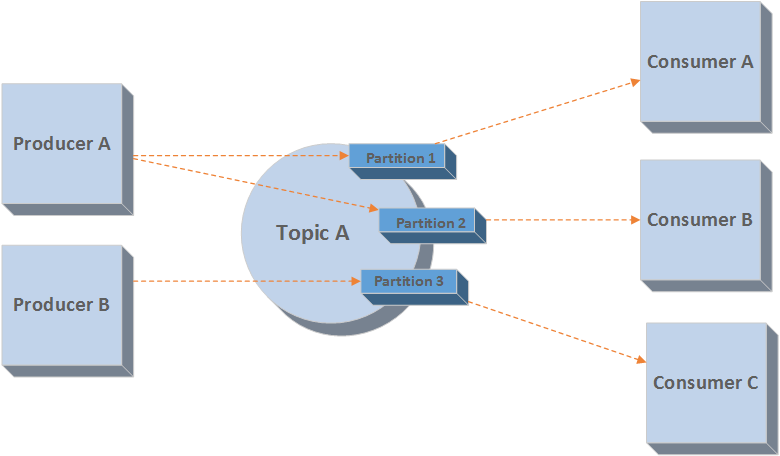
ข้อมูลที่จัดเก็บในแต่ละ partition นั้น
จะเรียงลำดับไปเรื่อย ๆ นั่นคือ
ข้อมูลเก่าจะอยู่ด้านหน้า
ข้อมูลใหม่จะอยู่ด้านหลัง
โดย consumer จะอ่านจากหน้าไปหลัง (อ่านตามค่า offset ในแต่ละ partition)
ที่สำคัญการอ่าข้อมูลของ consumer มีหลายรูปแบบอีกด้วย ไว้จอธิบายใน blog ต่อ ๆ ไป
แสดงดังรูป
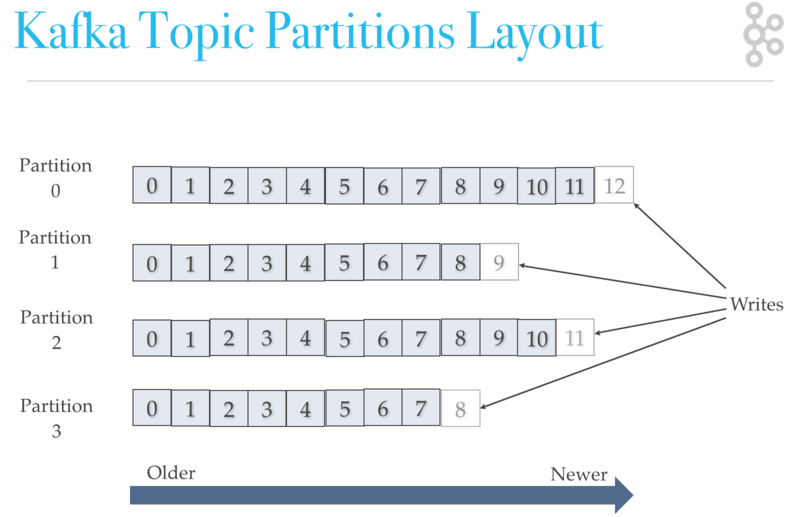
จากรูปในแต่ละ partition นั้นข้อมูลจะถูกเรียงลำดับเสมอ
คำถามที่น่าสนใจคือ ข้อมูลแต่ละตัวจะไปลง Partition ด้วยเงื่อนไขอะไร ?
ง่าย ๆ คือ ข้อมูลจะมี key มาด้วยหรือไม่
ซึ่ง key ก็เป็น property หนึ่งข้อมูลมูลที่ producer ส่งเข้ามา
ถ้ามี key มาด้วยจะทำการ hash key จึงจะได้ partition ที่จัดเก็บ
ถ้าไม่มีจะทำการเลือกแบบ Round-Robin
ทำให้เราสามารถมีแนวทางในการออกแบบเยอะขึ้น
คำถาม จำนวน partition ยิ่งมากยิ่งดีหรือไม่ ?
Partition บางครั้งจถูกเรียกว่า Unit of parallelism
นั่นหมายความว่า ยิ่งมีจำนวนมาก ยิ่งรองรับการทำงานที่สูงขึ้น
แต่ก็ไม่ใช่จะกำหนดเป็นตัวเลขมาก ๆ
เพราะว่า ยิ่งมาก partition ยิ่งกระจายไปแต่ละเครื่องมากขึ้น
ทำให้เกิด delay time มากขึ้น
Delay Time = (Number of Partition/replication * Time to read metadata for single partition)
และยังทำให้ฝั่ง Producer ต้องใช้ memory เยอะขึ้นด้วย
เพราะว่าการทำงานภายในจะต้องเก็บข้อมูลลงใน buffer ก่อนส่งไป
ดังนั้นจำนวนของ partition จึงเป็นเรื่องที่สำคัญ
มาดูกันว่า ส่วนการทำงานต่าง ๆ ทำงานร่วมกันได้อย่างไร ?
โดยปกติแล้ว Kafka จะไม่ทำงานเพียงเครื่องเดียว
แต่จะทำงานเป็น cluster หรือเรียกว่า Kafka cluster หรือมีการทำงานร่วมกันหลาย ๆ เครื่อง
topic ต่าง ๆ จะถูกกระจายไปยัง Kafka broker
ทำให้ Kafka cluster รองรับการเขียนละอ่านข้อมูลได้ดียิ่งขึ้น
และเพื่อความปลอดภัยของระบบควรมี Kafka broker อย่างต่ำ 3 หรือ 5 ตัวเสมอ
Kafka broker นั้นจะทำงานแบบ stateless
ดังนั้นถ้าต้องการทำงานกับส่วนอื่น ๆ ใน Kafka cluster ก็ต้องมีตัวจัดเก็บ state ต่าง ๆ
นั่นก็เป็นหน้าที่ของ Zookeeper
แสดงดังรูป
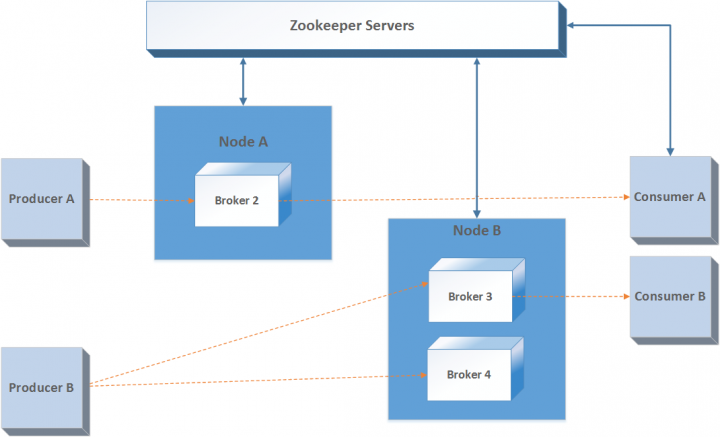
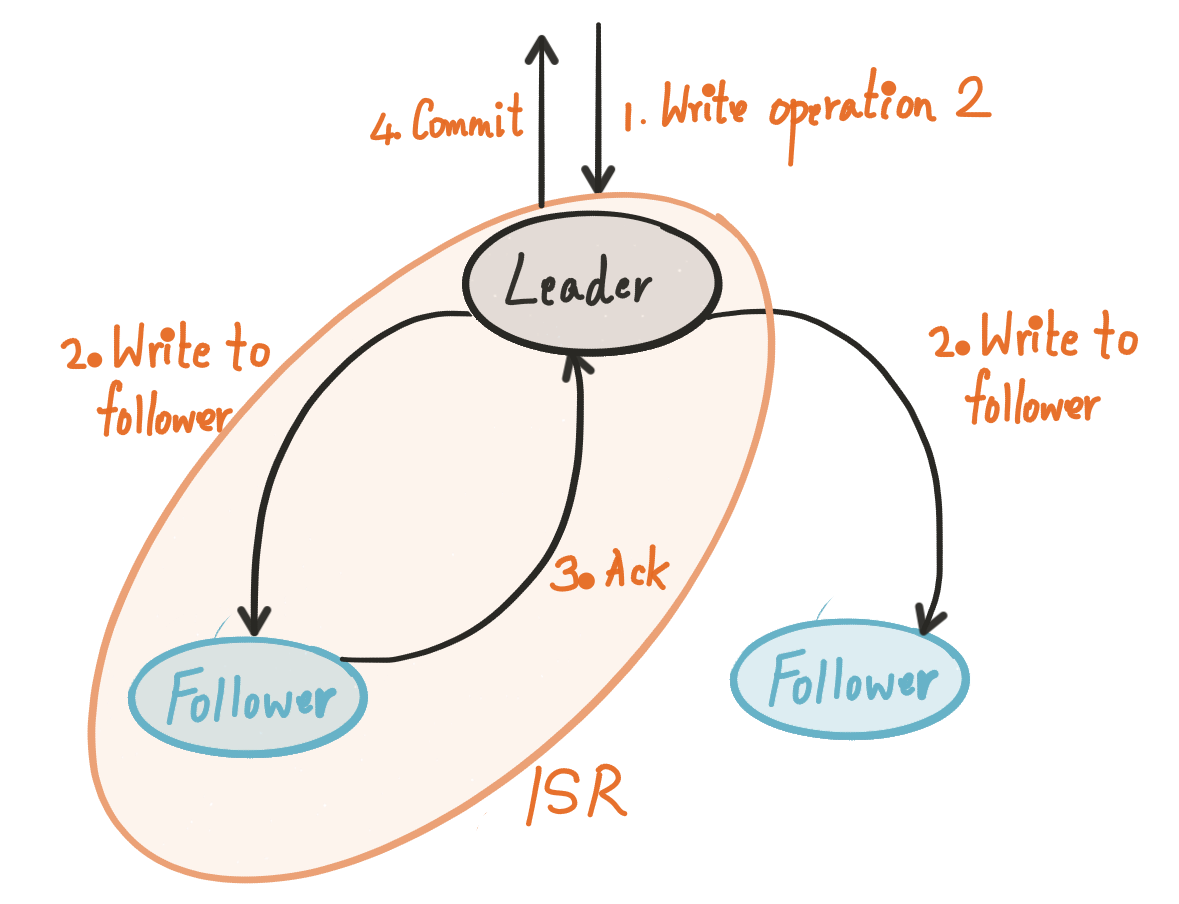
ยังไม่พอนะ แต่ละ partition ของแต่ละ topic ที่จัดเก็บใน Kafka broker หลักหรือเรียกว่า Leader
ทำหน้าจัดการการอ่านเขียนนั่นเอง
และจะมีการจัดเก็บไว้ใน Kafka broker ที่มีสถานะเป็น Follower ด้วย
ซึ่งจะทำ replicate ข้อมูลมาเก็บไว้ เป็นการ backup นั่นเอง
ตรงนี้ขึ้นอยู่กับการ configuration ในส่วนของ relication factor
Follower นั้นจะถูกเลือกมาเป็น Leader เมื่อ Leader เกิด fail ขึ้นมา
คำถามคือใครเป็นคนเลือก Leader ?
ตอบง่าย ๆ คือ Zookeeper ไงละ
ปล. ถ้า Zoopkeeper ตายไปนี่ บรรลัยได้เลย
ดังนั้นในการใช้งานจริง ๆ Zookeeper ไม่ควรมีเครื่องเดียวนะครับ
การ Replicate นั้นเป็นสิ่งที่สำคัญมาก ๆ ของ Kafka
มันทำให้เรามั่นใจได้ว่า ข้อมูลไม่หายไปไหนแน่ ๆ (ถ้าไม่โชคร้ายแบบสุด ๆ นะ)
โดยรูปแบบของการจัดการ replicate ของ Kafka มี 2 แบบคือ
- ISR (In-sync replication) ทำการ replicate ข้อมูลไปยัง follower ตามจำนวนที่กำหนด
- Primary-backup ทำการ replicate ข้อมูลไปยัง follower ทั้งหมด
มาถึงตรงนี้น่าจะเห็นได้ว่า Kafka มีส่วนการทำงานเยอะเลย
- Producer
- Consumer
- Broker
- Topic
- Partition
- Replication
- Zookeeper
ใน Part ต่อไปจะสรุปเกี่ยวกับการนำไปใช้งานตาม usecase และ workshop
รวมถึงทำความเข้าใจการทำงานของ Producer และ Consumer
โดย Kafka นั้น
Producer จะทำหน้าที่ส่งข้อมูลมายัง Broker เท่านั้น นั่นคือ Dumb Producer
ส่วน Consumer นั้นจะทำงานได้หลากหลายมาก ๆ นั่นคือ Smart Consumer
แน่นอนว่าได้เวลาเขียน code กันแล้ว
Reference Websites
http://cloudurable.com/blog/kafka-architecture-topics/index.html
https://www.confluent.io/blog/enabling-exactly-kafka-streams/





