วันนี้ทางทีมพัฒนาของ Twitter ได้ประกาศออกมาว่า
ตอนนี้สามารถค้นหาข้อมูล public tweet ได้ทั้งหมดแล้ว
ดังนั้นมาดูกันว่าการพัฒนาของ twitter เป็นอย่างไร
และมีโครงสร้างการทำงานอย่างไรกันนะ
ข้อมูลจาก blog
Today, we are pleased to announce that Twitter now indexes every public Tweet since 2006
โดยมีข้อมูลตั้งแต่ tweet แรกของ Jack Dorsey ในปี 2006 จนถึงปัจจุบัน
โครงสร้างระบบการค้นหาของ twitter นั้นต้องรองรับ
- การ index ข้อมูลประมาณเกือบ 1 ล้านล้าน เอกสาร
- การดึงข้อมูลที่มี latency เฉลี่ยต่ำกว่า 100 ms
เขาทำกันอย่างไรนะ เริ่มต้นมาดูส่วนสำคัญสำหรับการออกแบบระบบก่อนนะ
1. Modularity
ทำการแยกระบบการค้นหาออกไปจากระบบกลาง
โดยทาง twitter ได้ทำการสร้างระบบ real-time index ขึ้นมา ชื่อว่า Earlybird
ทำให้สามารถทดสอบระบบงานไปกับระบบจริงๆ ได้ง่าย
2. Scalability
เนื่องจากข้อมูลในระบบมีจำนวนมาก รวมทั้งอัตราการเพิ่มของข้อมูลสูงมาก
เนื่องจากในแต่ละสัปดาห์ข้อมูลเพิ่มเข้ามาประมาณหลายพันล้านเอกสาร
ดังนั้นจึงต้องการระบบที่สามารถรองรับการขยายตัวได้ดี
รวมทั้งเรื่องการ operation ต้องมี overhead น้อยๆ ด้วย
3. Cost effectiveness
ระบบ real-time index และ full index นั้นทำการเก็บข้อมูลไว้ที่หน่วยความจำชั่วคราว (RAM)
เพื่อทำให้ latency ต่ำ และมีการ update ข้อมูลที่รวดเร็ว
เป็นสิ่งที่ช่วยลดค่าใช้จ่ายทาง hardware ได้ดีมาก
4. Simple interface
สำหรับการขยายระบบให้รองรับข้อมูลจำนวนมากๆ นั้น
จำเป็นต้องทำการ partition ข้อมูล
ดังนั้นจำเป็นต้องมีระบบช่วยที่เรียบง่าย
5. Incremental development
ทางทีมงานมีเป้าหมายหลักก็คือ Index Every Tweet
แน่นอนว่ามันไม่สามารถสร้างเสร็จภายในเวลาอันสั้น
โดยระบบนั้นเริ่มจากปี 2012 สร้างระบบเพื่อ index ข้อมูล tweet ที่ได้รับความนิยม
จำนวน 2 พันล้านเอกสารก่อน เรียกระบบว่า Small history index
ซึ่งทำการประมวลผลแบบ offline
ต่อมาในปี 2013 ทำการขยายระบบ และ ปรับปรุงประสิทธิภาพด้วยการใช้ SSD
และในปี 2014 สร้างระบบ full index ที่มีเป้าหมายในการรองรับข้อมูลขนาดใหญ่
และการจัดการที่ง่าย เช่น การ partiion ข้อมูล และจัดการ cluster
มาดูโครงสร้างของระบบกันหน่อยสิ
ระบบการค้นหาประกอบไปด้วย 4 ส่วนการทำงานหลัก ดังนี้
- Batch data aggregation และ preprocessing
- Inverted index building
- Earlybird shards
- Earlybird root
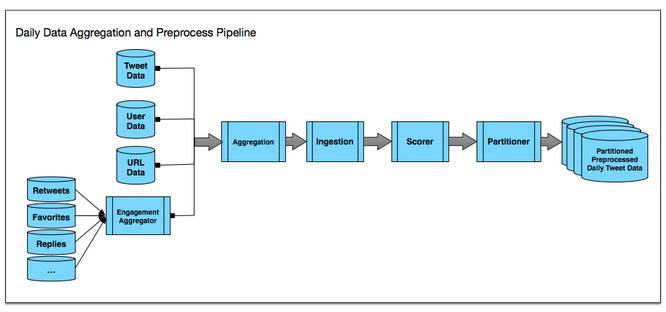
1. Batch data aggregation และ preprocessing
ในระบบประกอบไปด้วย 2 ส่วนคือ
- Real-time index ทำการ index ข้อมูลในแต่ละ tweet ทันทีเมื่อเกิดขึ้นมา
- Full index ทำการ index แบบ batching ของ tweet ที่เกิดขึ้นในแต่ละวัน
โดยทั้งสองส่วนจะใช้ code จะมีลักษณะเหมือนกัน แต่ทำงานในช่วงเวลาที่ต่างกัน
ทำให้ระบบการทำงานมีประสทิธิภาพมากขึ้น
รูปแสดงการทำงานเป็นดังนี้
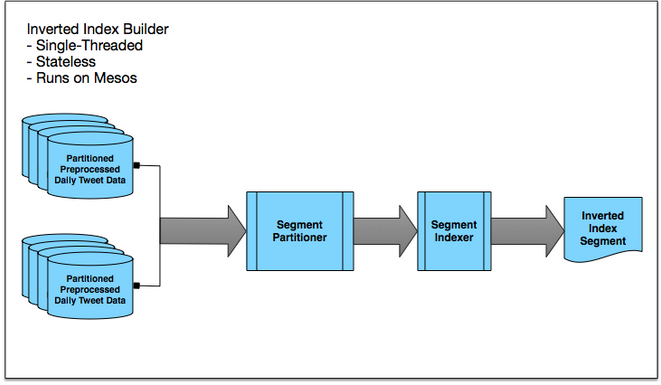
2. Inverted index building
ผลลัพธ์ที่ได้จากการข้อที่ 1 นั้น ข้อมูลในแต่ละ tweet จะถูกแบ่งคำออกมา
แต่ไม่ได้ทำการสร้าง inverted index
เพื่อช่วยเพิ่มประสิทธิภาพในการค้นหาข้อมูลให้ดีขึ้นมากๆ
เพื่อใช้การจับคู่ระหว่างคำหรือ index กับ ข้อมูลนั่นเอง
โดยจะทำการเก็บ inverted index ไว้ใน HDFS
ทีมพัฒนาบอกว่าใช้เวลา 2 วัน สำหรับการสร้าง inverted index
ข้อมูลจำนวนกว่า 1 ล้านล้านเอกสาร
โดยพบว่าปัญหาคอขวดอยู่ที่ Hadoop namenode
รูปแสดงการทำงานเป็นดังนี้
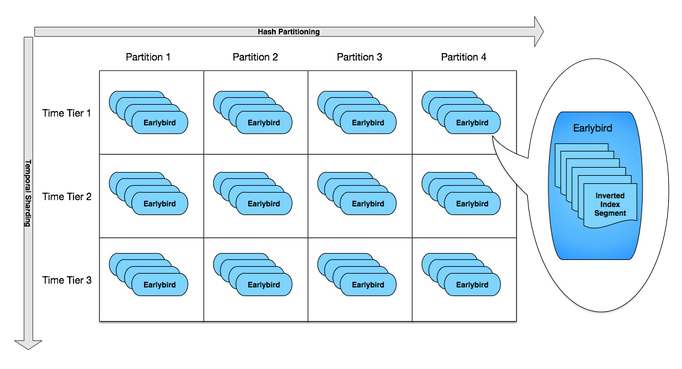
3. Earlybird shard
ผลจากข้อ 2 คือ inverted index จะถูกกระจายไปยังเครื่องต่างๆ ซึ่งเรียกว่า Earlybird
นั่นคือเป็นวิธีการทำงานแบบ Sharding นั่นเอง
โดยการกระจายนั่นจะใช้ทั้ง hash function และ temporal sharding
เพื่อทำให้สามารถเพิ่มหรือขยาย cluster ได้ง่ายและมีประสิทธภาพมากยิ่งขึ้น
รูปแสดงการทำงานเป็นดังนี้
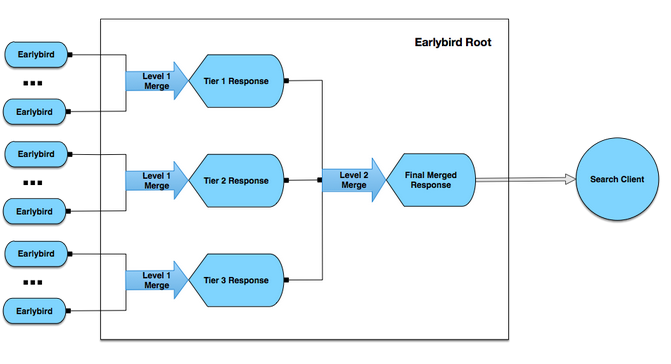
4. Earlybird root
จากข้อ 3 ได้ทำการกระจายข้อมูลไปยัง Earlybird กันแล้วนั้น
สิ่งที่ยังขาดไปก็คือ Client API สำหรับการเข้าถึงข้อมูล
เนื่องจากข้อมูลได้กระจายในแต่ละ partition และ time tier นั้น
คงไม่อยากให้ผู้ใช้งานทำการดึงข้อมูลเอง เนื่องจากมันซับซ้อนเกินไป
ดังนั้นจึงสร้าง Client API แบบง่าย ชื่อว่า Earlybird root ให้ดีกว่า
ซึ่งมันช่วยซ่อนการทำงานที่ซับซ้อนไว้ให้
รูปแสดงการทำงานเป็นดังนี้
ดังนั้นจากแนวคิดและโครงสร้างการทำงานของระบบการค้นหาของ Twitter
ทำให้เราสามารถค้นหาข้อมูลได้ทั้งหมด ในทุกๆช่องทาง
เป็นแนวทางหนึ่งสำหรับการสร้างระบบการค้นหาข้อมูลที่ต้องเรียนรู้กันไว้ครับ