จากบทความเรื่อง A Brief History of Scaling LinkedIn
ได้ทำการอธิบายสถาปัตยกรรมของระบบ LinkedIn
ตั้งแต่ปี 2003 จนถึงปัจจุบัน
จากผู้ใช้งาน 2,700 คนในสัปดาห์แรกของการเปิดระบบ
จนถึงปัจจุบันมีผู้ใช้งานกว่า 350 ล้านคน
มาดูกันหน่อยสถาปัตยกรรมของระบบมีความเป็นมาอย่างไรบ้าง ?
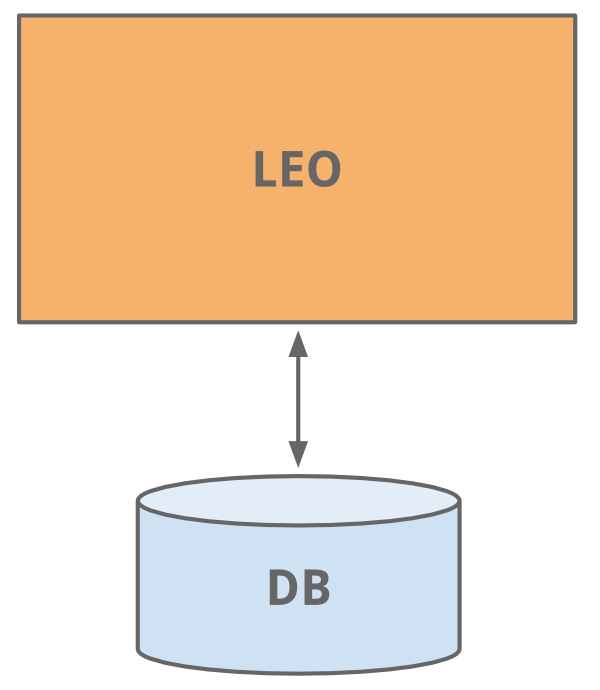
ช่วงที่ 1 เรียบง่ายมากๆ คือ 2-tier
นี่คือสถาปัตยกรรมเริ่มต้นของระบบ มันเรียบง่ายมากๆ แบ่งเป็นสองส่วน คือ
- Servlet สำหรับรองรับ request จากผู้ใช้งาน และ ประมวลผล
- Database สำหรับเก็บข้อมูลทุกๆ อย่างของระบบ
แสดงดังรูป
ระบบ LinkedIn นั้นจะเป็น Social Network สำหรับคนทำงาน
ดังนั้นตอนเริ่มต้นต้องมีเรื่อง Member Graph หรือการเชื่อมโยงของสมาชิกนั่นเอง
เป็นระบบที่แยกออกมาจากส่วนแรก หรือ (Leo)
ข้อมูลต่างๆ จะอยู่ใน memory ทั้งหมด
ซึ่งทำให้มีประสิทธิภาพในการทำงานสูง
โดยในส่วนการค้นหาข้อมูลนั้นใช้งาน Lucene
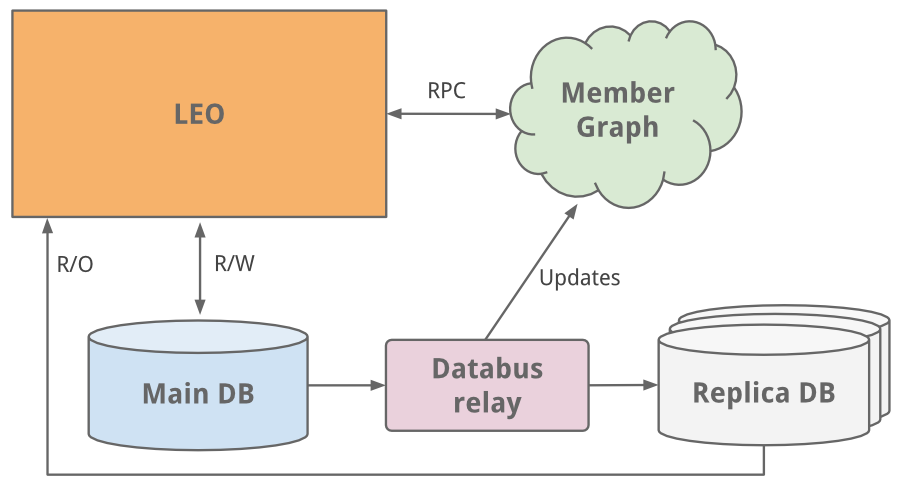
แน่นอนว่าระบบ Web (Leo) นั้นต้องทำงานร่วมกับระบบ Member Graph สิ
ซึ่งติดต่อกันผ่าน Java RPC
ช่วงที่ 2 เมื่อระบบใหญ่ขึ้น ความซับซ้อนสูงขึ้น
ระบบ Leo เริ่มมีหน้าที่ความรับผิดชอบสูงขึ้นอย่างมาก
ส่วน Leo ก็มีหลายเครื่องมากขึ้น และ นำ Load balance มาช่วยกระจายงาน
แต่ส่วนที่อาการหนักมากๆ คือ Member profile database
ทำการแก้ไขปัญหาด้วยวิธีการสุด classic นั่นคือ Vertical scaling
คือการเพิ่ม CPU และ Memory ซึ่งสามารถซื้อเวลาได้ เพื่อหาวิธีการอื่นๆ
จากนั้นเริ่มทำการแก้ไขส่วนของ Member profile database
ด้วยแนวคิด Master-slave หรือการ replicate ข้อมูล
จาก Master database ไปยัง Slave database
โดยในการ replicate ใช้การ sync ผ่าน Databus
ระบบดังกล่าวเป็นดังรูป
ช่วงที่ 3 เข้าสู่ยุดของ Service Oriented Architecture (SOA)
เมื่อระบบมีผู้เข้าใช้งานสูงขึ้น ทำให้ระบบ Leo มันล่มบ่อยมากๆ
ทำการ recovery ระบบยากมากขึ้นเรื่อยๆ
รวมทั้งการเพิ่ม code และ feature ใหม่เข้าไปยากขึ้นอีก
โดยที่ LinkedIn เรื่อง High Availability เป็นสิ่งที่สำคัญมากๆ
ดังนั้นถึงเวลาต้อง ทำลายระบบ Leo แล้ว
เนื่องจากระบบมันใหญ่เกินไปแล้วว
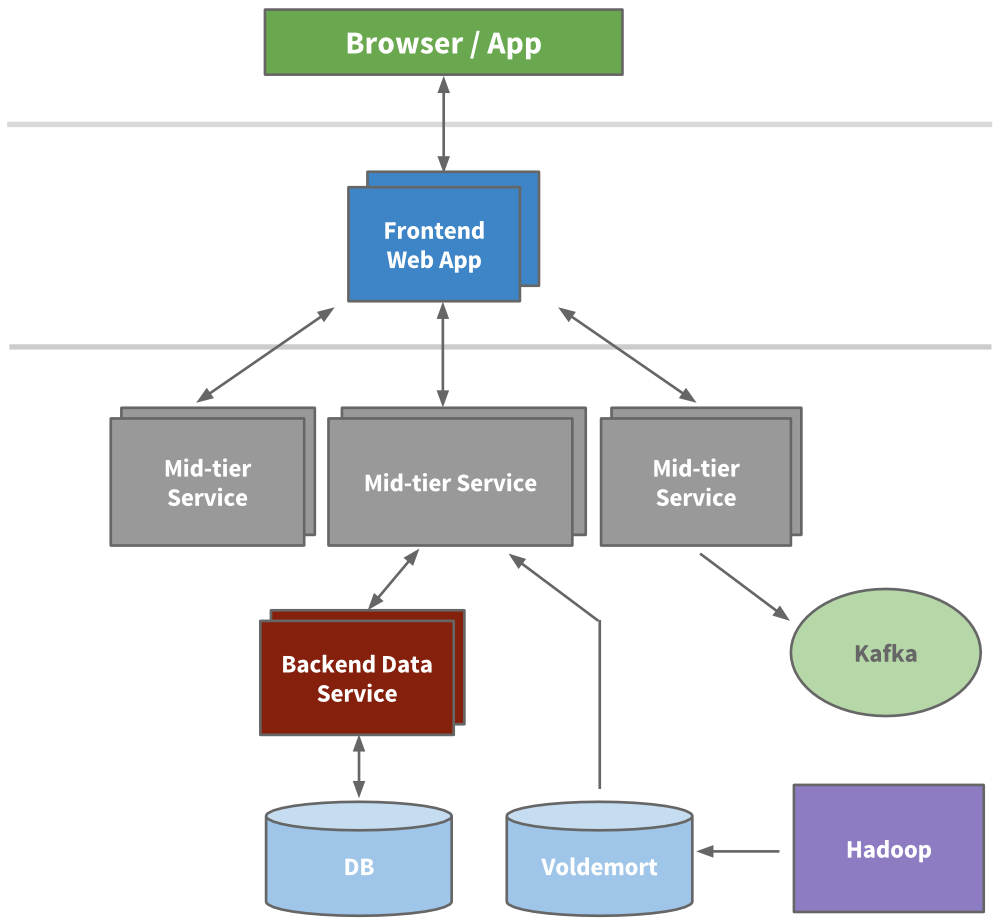
ดังนั้นจึงทำการแยกส่วนการทำงานเป็นระบบย่อยๆ
และแต่ละระบบจะทำงานเป็นแบบ Stateless อีกด้วย
นั่นคือ เข้าสู่ยุคของ SOA
แต่ละการทำงานหรือ service จะเป็นส่วนทำงานเล็ก (Micro service)
ซึ่งจะมี APIs และ business logic ของตัวเอง เช่น
- ระบบ search
- ระบบ profile
- ระบบ communication
- ระบบ group
ในส่วนของการแสดงผล หรือ Presentation หรือ Frontend
จะทำการดึงข้อมูลจากแต่ละ service มาแสดงผลต่อไป
พัฒนาด้วย HTML และ JSP (Java Server Page)
ในปี 2010 นั้นทาง LinkedIn มี 150 service
ส่วนในปัจจุบันมีมากกว่า 750 service
แสดงโครงสร้างของระบบดังรูป
เนื่องจากแต่ละ service มันทำงานแบบ Stateless
ทำให้การเพิ่ม node หรือเครื่อง service ใหม่ทำได้ง่าย
ยังไม่พอนะ แต่ละ service นั้นยังเพิ่มเรื่องของ monitoring และ provisioning ไว้ด้วย
ต่อจากนี้ทำให้เกิดเครื่องมือ และ framework ต่างๆ อีกมากมาย ทั้ง
- Kafka
- Inversion
- Rest.li
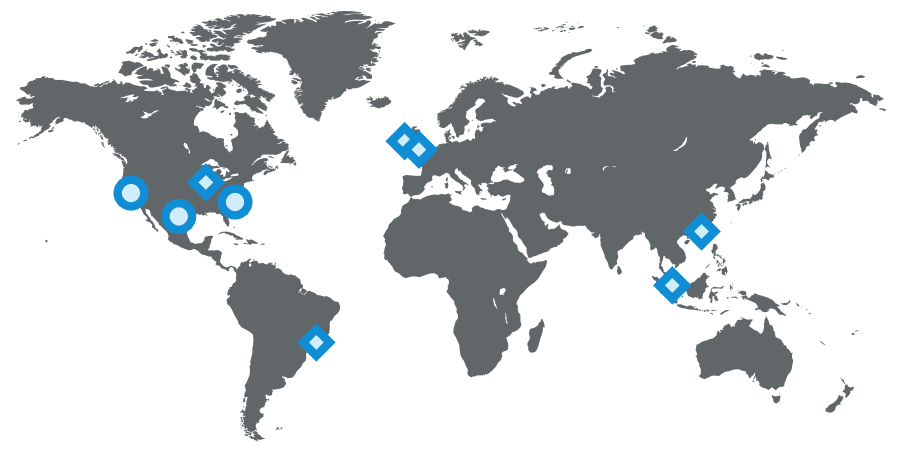
จากนั้น เมื่อระบบเป็นที่นิยมใช้จากส่วนต่างๆ บนโลกใบนี้
ทำให้ Data Center ที่เดียวมันไม่เพียงพอ
ดังนั้นจึงเริ่มสร้าง Data Center ในส่วนต่างๆ ของโลก
แสดงดังรูป
เราได้อะไรจากสิ่งต่างๆ เหล่านี้บ้างล่ะ ?
ทาง LinkedIn ได้เรียนรู้ว่า การ scaling นั้นมันไม่ง่ายเลย
ดังจะเห็นได้จากวิวัฒนาการของ service ต่างๆ
รวมทั้งยังก่อให้เกิดเครื่องมือใหม่ๆ
ที่สร้างขึ้นมาเพื่อรองรับความต้องการของระบบที่โตขึ้นอย่างมาก
แต่อย่างไรก็ตามทีมงานก็ยังคงปรับปรุงอย่างต่อเนื่อง และ ไม่หยุดยั้ง
ทั้งทางด้าน hardware และ software
และยังคงเรียนรู้จากปัญหากันต่อไป
คุณล่ะ ได้อะไรจากบทความนี้ของ LinkedIn บ้าง ?
สามารถอ่านเพิ่มเติมได้ที่นี่
A Brief History of Scaling LinkedIn