ในช่วงวันหยุดหยิบหนังสือ Release It 2nd edition มาอ่าน
เน้นบทที่ 6 ว่าด้วยเรื่อง Stability Patterns
ซึ่งอธิบายถึงรูปแบบของการวางสถาปัตยกรรมของระบบที่ดี
เป็นแนวทางในการออกแบบระบบ
เพื่อลด ขจัดปัดเป่า จากปัญหาต่าง ๆ ที่อาจจะเกิดขึ้น
หรือลดความอันตรายจากข้อผิดพลาดต่าง ๆ ลงไป
ไม่ใช่ต้องตื่นมากดึก ๆ เพื่อมาแก้ไขระบบ
ไม่ใช่ต้องยกเลิกงานทั้งหมด เพื่อมาแก้ไขระบบ
ถ้าเป็นแบบนี้คงไม่ต้องทำอะไรกันพอดี !!
ดังนั้นมาสร้างระบบดี ๆ กันหน่อย
โดยในหนังสือนั้นมีรูปแบบที่แนะนำมากมาย

ประกอบไปด้วย
- Timeout
- Circuit breaker
- Bulkheads
- Steady state
- Failfast
- Let It crash
- Test harnesses
- Decouple middleware
- Shed load
- Create back pressure
- Governor
มันจะเยอะไปไหนเนี่ย ?
มาดูรายละเอียดแบบคร่าว ๆ ของแต่ละเรื่องกันหน่อย
ซึ่งเลือก Timeout กับ Circuit breaker มาอธิบาย เพราะว่าน่าจะใช้บ่อยสุดแล้ว
แต่เรื่องอื่น ๆ ก็น่าสนใจและจำเป็นต้องรู้เช่นกัน
มาเริ่มกันดีกว่า
Timeout
น่าจะเป็นเรื่องปกติ ๆ ที่ใคร ๆ ก็ต้องกำหนด timeout
หรือเวลาการรอสิ่งต่าง ๆ
ยกตัวอย่างเช่น
- การเชื่อมต่อไปยัง service ต่าง ๆ
- การเชื่อมต่อผ่านระบบ network
- การเชื่อมต่อไปยัง remote file system
ซึ่งระบบ network สามารถเกิดข้อผิดพลาดได้เพียบ
ทั้งสายสัญญาณพัง
ทั้งสายหลุด
ทั้งถูกรบกวนการทำงาน
ทั้งอุปกรณ์ต่าง ๆ ระหว่างผู้ใช้และผู้ให้บริการมีปัญหา
ทั้งทำงานช้า
ทั้งผู้ใช้งานเยอะ
เยอะไปไหน !!
จากบทความเรื่อง Microservices Aren’t Magic: Handling Timeouts
อธิบายเรื่องของ Timeout ได้อย่างน่าสนใจ ลองอ่านเพิ่มเติมได้
ถ้าหมดเวลาที่รอแล้วก็จะโยน error ออกมา
จากนั้นก็ทำการจัดการหรือ handle ต่อไป ว่าจะทำอย่างไรต่อไป
ขึ้นอยู่กับ use case ของการทำงาน
เช่น
- แจ้งผู้ใช้งานไปว่าระบบมีความผิดพลาด ให้ลองใหม่
- ระบบทำงาน retry หรือลองทำงานใหม่อีกครั้ง ซึ่งจะมีการกำหนด interval การทำงานหใม่อีกด้วย รวมทั้งมีจำนวนการ retry สูงสุดไว้ด้วย
ดังนั้นเราทำการกำหนด timeout ของการทำงานผ่านระบบ network ไว้หรือยัง
เพราะว่าส่วนใหญ่จะไม่กำหนดนะ
หรือหนักกว่านั้น ทำการกำหนด timeout ไว้นานมาก ๆ
นั่นคือผู้ใช้งานต้องรอไปเรื่อย ๆ หรือ ตลอดไปหรือไงนะ !!
ยังไม่พอ
ในระบบของเรานั้นมีส่วนจัดการเกี่ยวกับ timeout กี่ที่กันนะ ?
ถ้าบอกว่าเยอะ หลายที่เลย หมายความว่า การจัดการลำบากมาก ๆ !!
ดังนั้นควรรวมมาไว้ที่เดียวดีกว่านะ
ยกตัวอย่างการใช้งาน gateway เพื่อจัดการเรื่อง
- การจัดการ connection ต่าง ๆ
- การจัดการความผิดพลาดต่าง ๆ
- การจัดการการดึงข้อมูลจาก database
- การจัดการการประมวลผลที่ใช้เวลานาน ๆ
จะทำให้เราจัดการปัญหาต่าง ๆ ที่เกิดขึ้นได้ง่ายขึ้น
ด้วยรูปแบบที่เรียกว่า Circuit Breaker ต่อไป
Circuit Breaker
ชื่อมันคุ้น ๆ นะ
ตัดก่อนตาย เตือนก่อนวายวอด นั่นมัน Safe-T-Cut นี่หว่า
มาดูในส่วนของ software กันบ้าง
หลังจากที่เกิดปัญหาขึ้นมาแล้ว เราจะทำอย่างไรกันต่อดี
ระบบที่ดีจะมีตัวจัดการ หนึ่งในนั้นคือ Circuit Breaker
ซึ่งมันต่างจากการ retry หรือการทำงานซ้ำ
เพราะว่า Circuit Breaker จะไม่ทำงานซ้ำในที่ ๆ มันพังอยู่
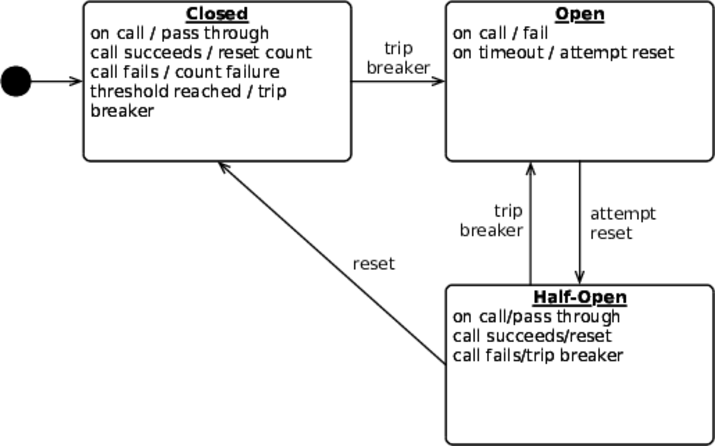
มาดูการทำงานของ Circuit Breaker หน่อย
ปกติจะมี 2 สถานะคือ ปิด กับ เปิด
ค่า default คือ ปิด
แต่เมื่อเกิดปัญหาขึ้นมา เช่น timeout แล้ว
Circuit Breaker จะทำการบันทึกจำนวนปัญหาไว้
เมื่อปัญหาต่าง ๆ ถึงจำนวนที่กำหนดหรือค่า threshold
จะเปลี่ยนสถานะจากปิดเป็นเปิด
นั่นคือไม่มีใครสามารถเรียกใช้งานการทำงานนั้น ๆ ได้
จนกว่าจะผ่านเวลาที่กำหนดไว้ (Timeout)
จากนั้นจะทำการค่อย ๆ เปลี่ยนสถานะของ Circuit Breaker จากเปิดไปเป็นเปิดครึ่งเดียว
นั่นคือ อนุญาตให้เรียกใช้งานส่วนงานนั้น ๆ ได้
ถ้าทำงานสำเร็จก็จะเปลี่ยนสถานะไปเป็นปิด นั่นคือใช้งานได้ปกติ
แต่ถ้าทำงานผิดพลาดเช่นเดิม ก็จะเปลี่ยนสถานะเป็นเปิด แล้วก็รอวนไป
แสดงการทำงานดังรูป
ส่วนการใช้งานจริง ๆ ก็แล้วแต่ use case อีกแล้ว
อาจจะไม่ต้องรอให้พังก็ได้ แค่ timeout ก็พอ
จากนั้นก็ทำการจัดการปัญหาในหลาย ๆ แบบ
ทั้งส่งรายละเอียดของปัญหาที่เข้าใจง่ายออกไปให้ผู้ใช้งาน
บางระบบ ก็ไปเปิดระบบงานใหม่ขึ้นมา หรือ route การทำงานไปยังที่ใหม่กันก็เป็นไปได้
และมักจะใช้สิ่งที่เรียกว่า Fallback เพื่อส่งค่าสำเร็จล่าสุด หรือ ข้อมูลที่ cache ไว้กลับไป
เพื่อลดผลกระทบที่จะเกิดขึ้นต่อระบบ แน่นอนว่ามันกระทบต่อ business แน่นอน
ดังนั้นสิ่งที่สำคัญมาก ๆ คือการคุยและตกลงกับเจ้าของระบบว่า
ถ้าเกิดปัญหาต่าง ๆ ขึ้นมา หรือ Circuit Breaker อยู่ในสถานะเปิดแล้ว
จะต้องจัดการอย่างไรบ้าง ?
อย่าให้แต่ทาง IT หรือทีมพัฒนาคิดละ !!
อีกอย่าง อย่าลืมเก็บ log การเปลี่ยนสถานะของ Circuit Breaker ด้วยนะ
เพื่อทำให้เราและ operation รู้การทำงานด้วย
โดยสรุป
ความผิดพลาดของระบบมันเป็นสิ่งที่หลีกเลี่ยงไม่ได้
แต่เราสามารถควบคุมพื้นที่ของความผิดพลาดให้เล็กได้ด้วยเทคนิคต่าง ๆ
บางครั้งความหวาดระแวงหรือตื่นตระหนกก็เป็นสิ่งที่ดี
ถ้าอยู่บนพื้นฐานของความมีเหตุมีผล
เพื่อทำให้เราสามารถเตรียมวิธีการรับมือไว้
ในวันหนึ่ง ๆ ระบบงานของเรามีจำนวน request เข้ามาเยอะเท่าไร
นั่นคือโอกาสที่เกิดข้อผิดพลาดก็เยอะมากขึ้นเท่านั้น
วันนี้คุณรับมือกับปัญหาต่าง ๆ ของระบบกันอย่างไร ?
หรือตามแก้ไขไปวัน ๆ