พอดีต้องทำงานกับ Vector Database ทั้ง
Pinecone, Milvus, Redis, Elasticsearch และ pgvector
เกิดคำถามว่าคืออะไร ทำงานอะไรได้บ้าง
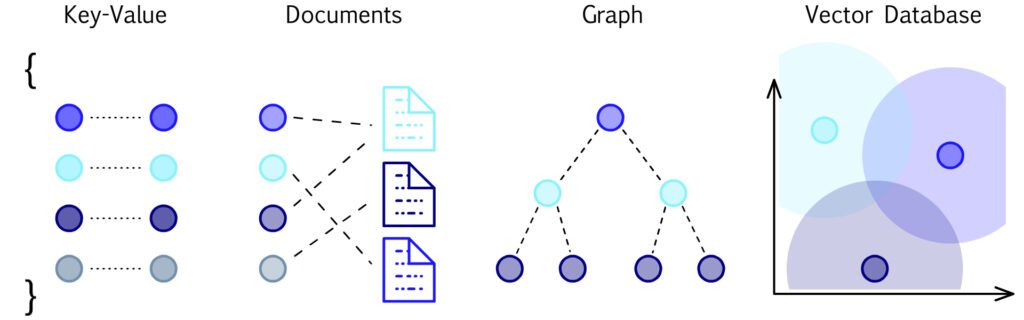
เนื่องจากปกติ NoSQL จะรู้จักแค่ key-value, column, document และ graph
พอมาเจอ Vector ก็เลยงง ๆ
ดังนั้นทำความรู้จักกันหน่อย
เนื่องจากระบบมีความซับซ้อนมากยิ่งขึ้น
ข้อมูลก็มีหลายหลายชนิด (Variety)
ทั้ง structure และ unstructure
ทำให้การจัดการยากลำบากมากขึ้น
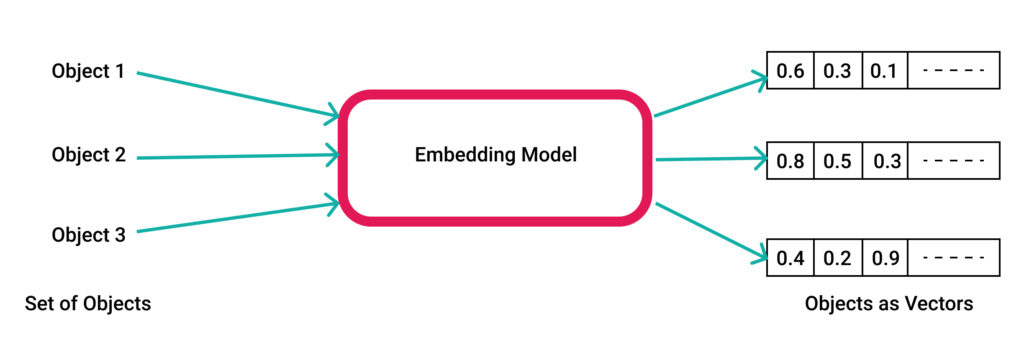
ในโลกของ Machine Learning (ML) ก็มีแนวคิดในการจัดการข้อมูลที่ซับซ้อน
ด้วยการแปลงหรือ transform ข้อมูลในรูปแบบของ vector embedding
ซึ่งนำเสนอในรูปแบบของตัวเลขในมิติต่าง ๆ
จากนั้นก็ต้องทำเก็บข้อมูลเหล่านี้ไว้ใน database
เพื่อให้สามารถนำไปใช้งานได้ต่อไป
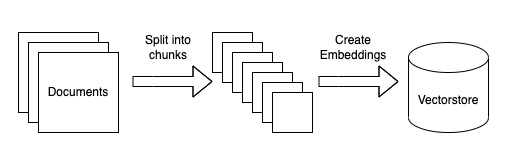
ช่วยจะทำการสร้าง index ไว้ให้
ทำให้การค้นหา หรือ similarity search ได้ดีขึ้น
การทำ CRUD ได้อยู่แล้ว
การ filter หรือ กรองข้อมูลมีประสิทธิภาพสูง
ง่ายต่อการ scale แบบเพิ่มเครื่อง หรือ Horizontal scaling
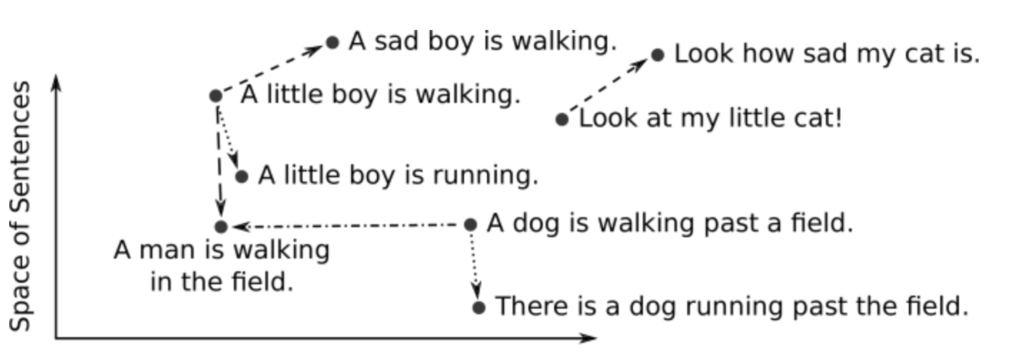
โดย use case ของ Vector embedding นั้นมีเยอะ เช่น
- Semantic search
- Similarity search เช่น รูปภาพ เสียง VDO หรือ JSON
- ทำระบบ ranking หรือ คำแนะนำต่าง ๆ
- การตรวจสอบ duplication ของข้อมูล หรือ การตรวจลิขสิทธิ์
เป็นอีก database model ที่น่าสนใจมาก ๆ
และจำเป็นต้องรู้และเข้าใจ
Reference Websites