Machine Learning ( ML ) คืออะไร ?
เป็นคำถามที่น่าสนใจมาก ๆ
ผมเชื่อว่า แต่ละคนย่อมให้ความหมาย
และ คำจำกัดความแตกต่างกันไป
ตามประสบการณ์ที่พบเจอมา
ผมไปอ่านเจอบทความเรื่อง Is Machine Learning about Machines Learning?
อธิบายได้ดี และ น่าสนใจ
จึงนำเอาแปล และ สรุปได้ดังนี้
Machine Learning คืออะไรล่ะ ?
อะไรก็ตามที่ช่วยเราหาคำตอบได้หลากหลายวิธีการ
จากคำถามหนึ่ง ๆ หรือ ปัญหาหนึ่ง ๆ
โดยเป็นวิธีการเชิงลึกมากกว่าที่เคยทำกันมาในอดีต
ซึ่งมันช่วยเราแก้ไขปัญหา
ที่เราอาจจะไม่เคยพบ และ แก้ไขมาก่อน
ลองไปหาข้อมูลเพิ่มดีกว่า
จาก Course Machine Learning ของ Stanford University
ให้คำจำกัดความไว้ว่า
Machine learning is the science of getting computers to act without being explicitly programmed.
แต่สิ่งที่เราต้องการมากกว่านั้น คือ
แนวทางในการวิเคราะห์ข้อมูล
ว่า Machine Learning นั้น
- มันมีวิธีการศึกษา เรียนรู้อย่างไร ?
- มันมี Algorithm อะไรบ้าง ?
- เพื่อช่วยทำให้สามารถทำนายผลอนาคตจากข้อมูลที่มีอยู่ได้
- มันเกี่ยวข้องกับวิชาคณิตศาสตร์มากใช่ไหม ?
Machine Learning มันแตกต่างจากสถิตินะ ?
เนื่องจากมันไม่ได้สนใจสาเหตุ หรือ ผลกระทบที่เกิดขึ้น
แต่มันสนใจที่ การทำนาย โดยไม่ต้องเข้าใจว่ามีเหตุและผลอย่างไร
แสดงว่า มันต้องคิดได้เองสินะ ?
ว่าแต่ Machine Learning มันจะเรียนรู้ คิดได้เอง และ แก้ไขปัญหาให้เราได้อย่างไรล่ะ ?
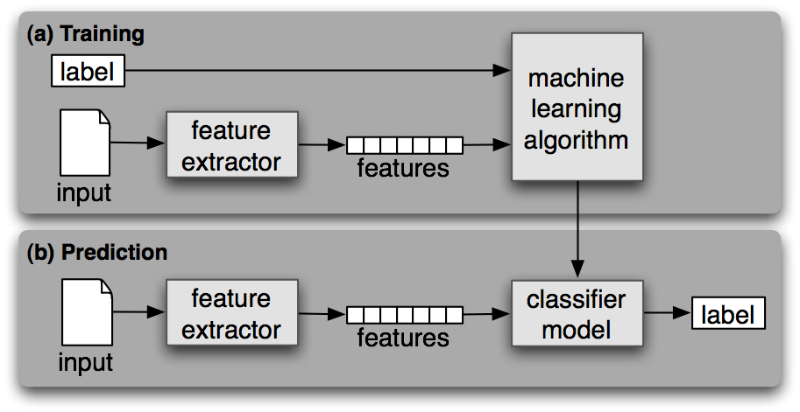
มีขั้นตอนการเรียนรู้เพื่อสร้าง model ของปัญหา ดังนี้
- Feature extraction ข้อมูลที่จะใช้ในการสร้าง model สำหรับปัญหาที่ต้องการ
- Regularization ทำการให้น้ำหนักและความสำคัญของข้อมูลที่จะใช้ในการสร้าง model
- Cross-validation ทำการตรวจสอบความถูกต้อง model
มาดูรายละเอียดกันหน่อย
1. Feature Extraction
เป็นกระบวนการแปลงข้อมูลให้อยู่ในรูปแบบ
ที่สามารถนำไปใช้งานได้ใน Machine Learning
เช่นแปลงจากข้อมูล text และ image
ไปอยู่ในรูปแบบชุดของตัวเลข
วิธีการนี้จะช่วยลดขนาดข้อมูลที่ต้องประมวลผลลงไปอีกด้วย
ซึ่งนั่นคือ การลด resource ที่ต้องใช้การประมวลผล
เป็นสิ่งสำคัญมาก ๆ ในโลกของ Big Data
2. Regularization
เมื่อเราทำการ extract feature ออกมาได้แล้ว
จากนั้นเราต้องพิจารณาว่า
อะไรคือสิ่งที่สำคัญต่อปัญหา
อะไรคือสิ่งที่ไม่สำคัญ เช่น noise
แต่บางครั้ง noise ก็มีความสำคัญนะ
เป้าหมายของ Regularization คือ
จัดการกับความซับซ้อนของ model
นั่นคือ ลดข้อมูลที่ไม่จำเป็นออกไป
เพื่อทำให้ได้ model ที่เรียบง่าย
3. Cross-validation
เมื่อเราทำการสร้าง model ออกมาแล้ว
เราต้องทำให้มั่นใจว่า model เหล่านั้นมัน ทำนาย ได้อย่างดีนะ !!
นั่นแสดงว่า ต้องทำการทดสอบ model นั่นเอง
ด้วยข้อมูลที่ไม่ได้นำมาสร้าง model
และข้อมูลนอกช่วงเวลา
จะเห็นได้ว่า
Model นั้นคือสิ่งที่สำคัญมาก ๆ สำหรับการแก้ไขปัญหา
ด้วย Machine Learning
แต่สิ่งที่สำคัญกว่า คือ การตั้งคำถาม และ กำหนดปัญหาที่ถูกต้อง
ไม่เช่นนั้น
ต่อให้ใช้วิธีการ และ algorithm
จนได้ model ที่ดีเพียงใดก็ไร้ค่า
ถ้าสร้างมาจาก คำถาม และ ปัญหาที่ผิด
สุดท้ายแล้ว คุณคิดว่า
Machine Learning คืออะไร ?