ในเรื่องของการ scale ระบบนั้น ถือเป็นเรื่องสำคัญ
โดยระบบที่ deploy ด้วย Kubernetes นั้น
สามารถจัดการแบบง่าย ๆ ด้วย Deployment และ ReplicaSet
แต่ก็ยังคงต้องทำแบบ manual
ดังนั้น Kubernetes จึงได้สร้าง Horizontal Pod Autoscaler (HPA) ขึ้นมา
เพื่อช่วยให้การ scale ในระดับ Pod แบบอัตโนมัติได้
โดยค่า default นั้นจะดูค่าจากการใช้งาน resource เช่น CPU เป็นต้น
รวมทั้งยังใช้งานยากพอสมควร
ถ้าสามารถทำการ custom ได้ รวมทั้งทำงานร่วมกับ metric อื่น ๆ ได้
น่าจะดีและมีประโยชน์กว่า
นั่นจึงเป็นที่มาของ Kubernetes Event Driven Autoscaling (KEDA)
โดยที่ Kubernetes Event Driven Autoscaling (KEDA) นั้น
เป็น opensource project ซึ่งสามารถทำงานร่วมกับ HPA ได้เลย
เราสามารถกำหนดและจัดเก็บ metric ในระดับ application
มาใช้สำหรับพิจารณาการ scale ระบบได้แบบง่าย ๆ
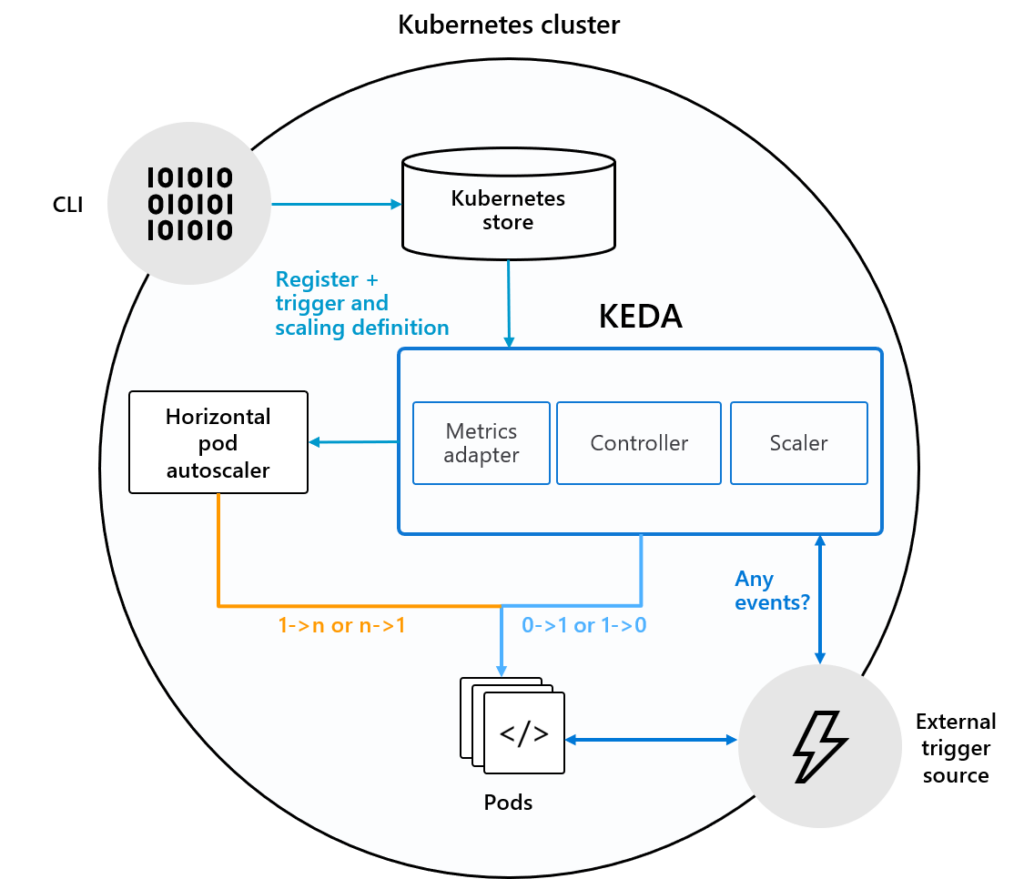
โครงสร้างของ KEDA แสดงดังรูป
สังเกตได้ว่า KEDA นั้นจะทำงานเหมือนกับ Metric server นั่นเอง
โดยที่เราสามารถสร้างและจัดเก็บ metric ของ application
เข้าไปได้จาก External trigger source
และเมื่อข้อมูล metric ใน KEDA เข้ารูปแบบที่กำหนด
ก็จะสั่งให้ HPA ทำงานตามที่ต้องการได้
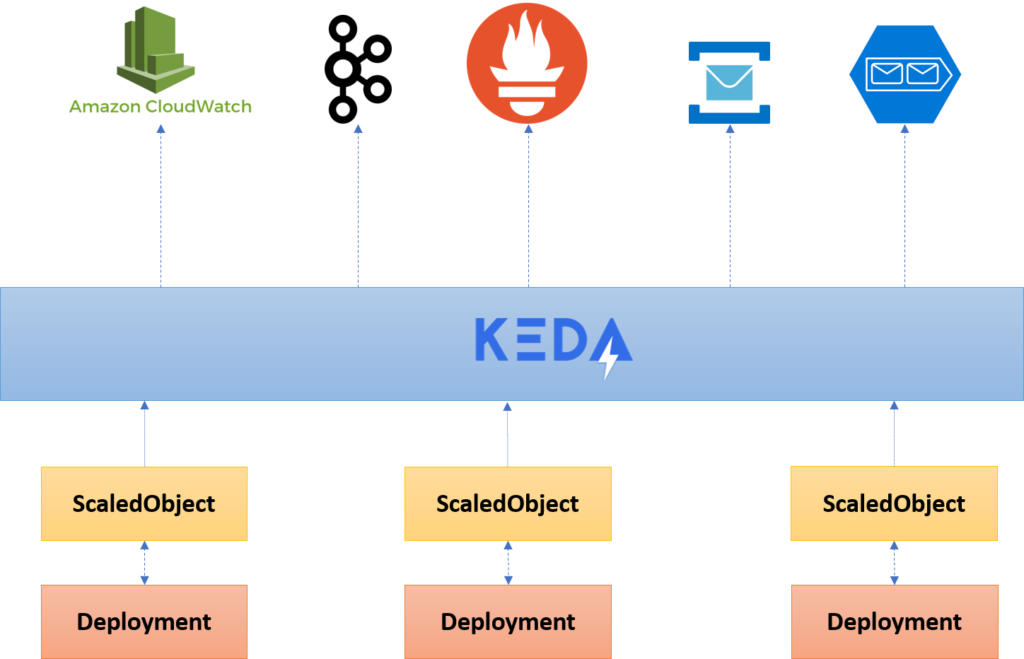
ดังนั้นเพื่อความเข้าใจ จึงทำการสร้างระบบงานง่าย ๆ
โดยจัดเก็บ metric ของระบบงานไว้ใน Prometheus
ตามจริง KEDA นั้นสนับสนุนทั้ง Redis, Kafka และ RabbitMQ อีกด้วย
แสดงดังรูป
มาเริ่มพัฒนาและใช้งานกัน
ขั้นตอนที่ 1 พัฒนาระบบงาน
ทำการเก็บข้อมูลการใช้งานของระบบงานไว้ใน Prometheus
ก่อนอื่นทำการตั้งโจทย์ว่า
จะทำการเก็บจำนวน request ทั้งหมดของการใช้งาน endpoint ที่ต้องการ
ซึ่งทำการสร้าง custom metric ชื่อว่า http_requests ขึ้นมา
ในรูปแบบของ Prometheus ดังนี้
ขั้นตอนที่ 2 การ deploy ระบบงาน และ prometheus บน Kubernetes cluster
แต่ตัวที่สำคัญคือ การ deploy KEDA เพื่อทำงานร่วมกับ Prometheus
โดยทำการสร้าง resource ชื่อว่า ScaledObject
เป็น custom resource (CRD) ของ KEDA นั่นเอง
เพื่อกำหนดการ scale ของ HPA ตามเงื่อนไขที่เราต้องการ
จากค่าตัวเลขหรือ metric ที่ทำการจัดเก็บไว้
เช่น ใน 1 นาทีล่าสุดถ้ามี request เข้ามาเกิน 5 request จะเริ่มทำการ scale
คำนวณง่าย ๆ คือ
ถ้ามีค่าเกิน 5 มาเช่น 15 จะทำการ scale Pod มาเพิ่มเป็น 3 (15/5)
แน่นอนว่า เราสามารถกำหนดจำนวนของ Pods ได้เอง
ทำการติดตั้งดังนี้
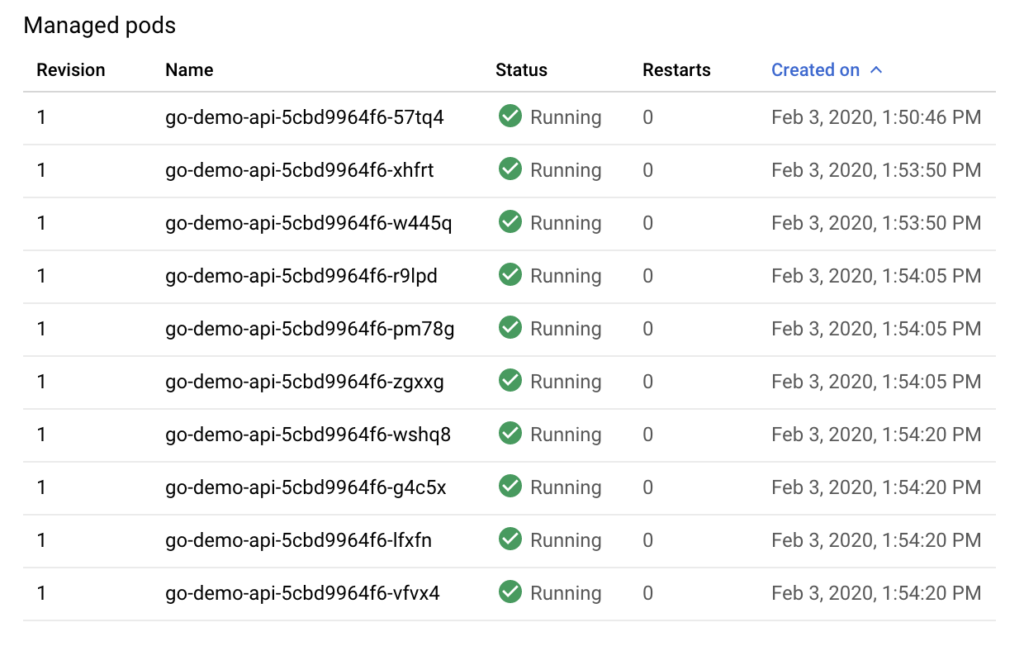
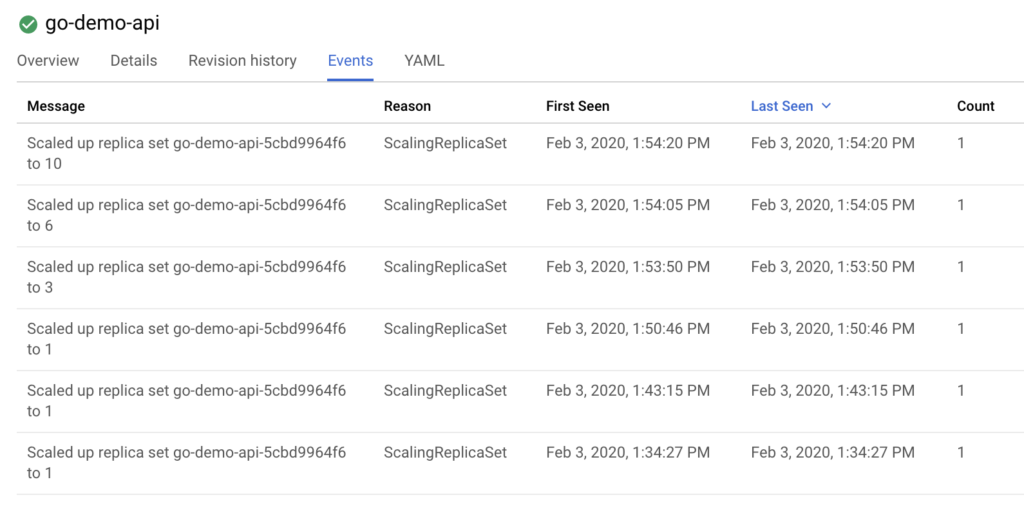
ขั้นตอนที่ 3 ทดสอบการ scale ด้วยการยิง load test นิดหน่อย
ผลที่ได้คือ ทำการสร้าง Pod ให้ตามที่เรากำหนดไว้เลย
ซึ่งกำหนดไว้สูงสุดที่ 10 Pods แสดงดังรูป
ดู event log ได้ดังนี้
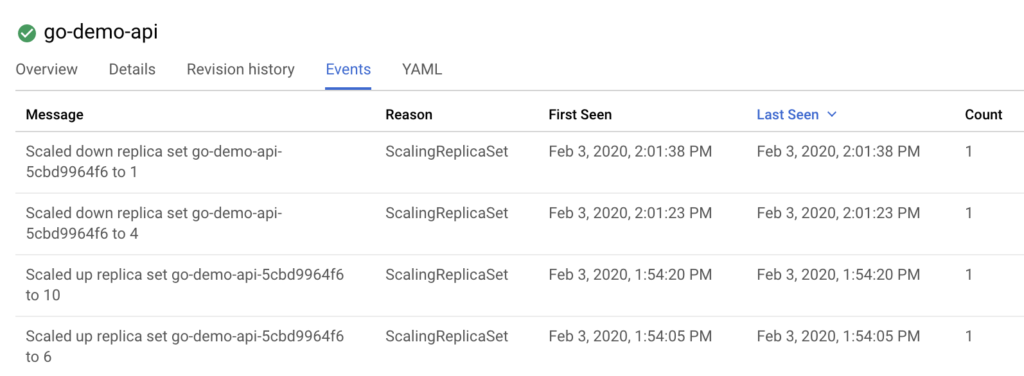
แต่เมื่อหยุดการยิง load test แล้วไปเกิน 1 นาทีแล้ว
พบว่า จำนวน Pod จะลดลงเรื่อย ๆ ไปจนถึง 1 ตามค่า min Pod ที่กำหนดไว้นั่นเอง
แสดงดังรูป
เพียงเท่านี้ก็สามารถ scale ระบบงานได้ตาม metric ที่ต้องการแล้ว
ทำให้พัฒนาระบบได้โดนใจและยืดหยุ่นมากยิ่งขึ้น
ตัวอย่าง source code ทั้งหมดอยู่ที่ GitHub::Up1
Reference Websites