
จากการพูดคุยกับหลายๆ คนที่ใช้ Elasticsearch
มักจะมีปัญหากับการจัดการกับข้อมูลภาษาไทย
ทั้งจากขั้นตอนการ Query และ Index ข้อมูล
วิธีการแก้ไขที่นิยมก็คือ ทำการตัดคำของข้อมูล
ก่อนส่งเข้าไปที่ Elasticseach
แต่ผมคิดว่า ไม่น่าจะเป็นแนวทางที่ดีหรือถูกต้องมากนัก
ดังนั้นจึงทำการหาวิธีแก้ไขด้วย การ Custom Analyzer
ผลจะเป็นอย่างไรมาดูกัน
จากที่ผมใช้งาน Apache Lucene และ Apache Solr มาเล็กน้อย
ก็พอจะรู้ว่าทั้งสองตัวมันสามารถตัดคำภาษาไทยได้ในระดับที่น่าพอใจ
( อยากให้ดีกว่านี้ต้องไปสร้างตัวตัดคำเอง หรือใช้ของ NECTEC ก็ได้ แต่ไม่มีใคร contribute ไปที่ต้นน้ำเลย )
ดังนั้นเมื่อมาใช้งาน Elasticsearch แล้วก็แปลกในนิดหน่อย
ว่าทำไมไม่เอาตัวตัดคำภาษาไทยมาใส่เป็นค่า default
เนื่องจาก Elasticsearch ก็สร้างอยู่บน Apache Lucene เช่นกัน
ลองทดสอบตัวตัดคำที่ถูก configuration มาตั้งแต่แรกกันว่าเป้นอย่างไร
ผ่าน http://localhost:9200/test กันดังรูป
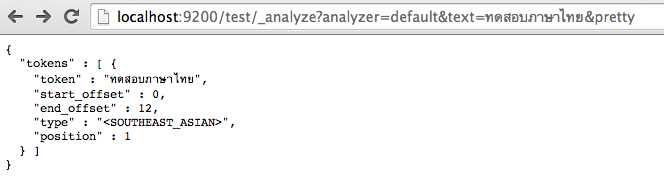
คำอธิบาย
จะสังเกตได้ว่า Elasticsearch มันรู้ว่าเป็นข้อมูลที่มาจาก South-East Asian นะ
ซึ่งแน่นอนมันรู้จักภาษาไทยอยู่แล้ว ไม่เชื่อไปดูข้อมูลเพิ่มเติมที่ Language Analyzer
แต่มันแค่ตัดคำภาษาไทยไม่ได้เท่านั้นเอง
ดังนั้นผมจึงลองเปลี่ยนค่าของ analyzer จาก default ไปเป็น thai ดูบ้าง
ผลคือ Error 404 นั่นคือไม่มี Analyzer thai สิ
ก็แน่นอน เพราะว่า ยังไม่ได้ทำการ configuration ไว้
ผลการทำงานดังรูป

จาก Error ดังกล่าวสามารถไปตามอ่าน code ได้จากไฟล์ TransportAnalyzeAction.java
แต่ไม่ต้องสนใจมันมากนัก เรามาทำการเพิ่ม Thai Analyzer เข้าไปดีกว่า
ยังใช้งานผ่าน test ของ Elasticsearch เช่นเดิม
โดยทำการ custom analyzer เข้าไป โดยเพิ่ม filter ใหม่ชื่อว่า thai เข้าไป
เพื่อให้ใช้งาน org.apache.lucene.analysis.th.ThaiWordFilterFactory อยู่ใน Apache Lucene นั่นเอง
ผลการทำงานผ่าน curl
จะแสดงคำว่า {“acknowledged”:true} ขึ้นมา เป็นอันสำเร็จเรียบร้อย
ต่อมาทดสอบด้วยตัว Analyzer ด้วย thai ตามที่เราสร้างไว้ผ่าน browser
แสดงผลการทำงานดังรูป ซึ่งสามารถตัดคำภาษาไทยได้เลย ง่ายมากนะ
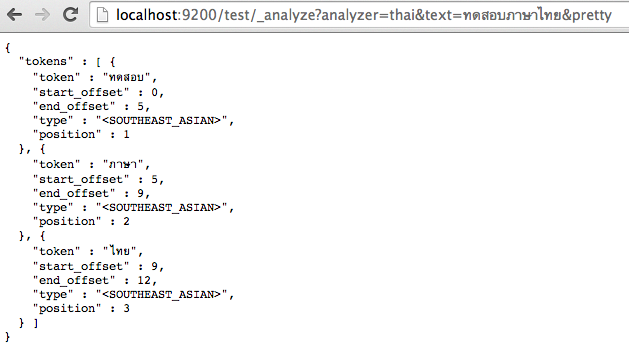
แต่ถ้าต้องการลบ Analyzer thai ออกไป จะคำสั่งดังนี้
curl -XDELETE http://localhost:9200/test
ต่อไปก็นำเอาไปใส่ไว้ในไฟล์ configuration ของ Elasticsearch
เพียงเท่านี้เราก็สามารถตัดคำภาษาไทย โดยใช้ ThaiWordFilterFactory
จาก Apache Lucene ได้แล้วครับ ง่ายใช่ไหมล่ะ !!!
ดังนั้น เราคงไม่ต้องมาตัดคำ ก่อนส่งเข้าไป Elasticsearch แล้วนะครับ
ลืมบอกไปว่า Software ที่ใช้ในการทดสอบ คือ Elasticsearch Community เวอร์ชั่น 1.1.1 ครับ





