ปัญหาที่พบเจอสำหรับการจัดเก็บข้อมูลใน Redis
นั่นก็คือ การเลือก data structure ที่ไม่เหมาะสมกับการใช้งาน
ส่งผลให้การทำงานในแต่ละ operation สูงขึ้น
ส่งผลให้ Redis รับงานได้น้อยลง
เนื่องจาก Redis ทำงานแบบ Single Thread นะ (แต่ก็ปรับปรุงมาเยอะ)
ดังนั้นจึงกลับมาดูที่ต้นเหตุ รวมทั้งความรู้พื้นฐานกันหน่อย
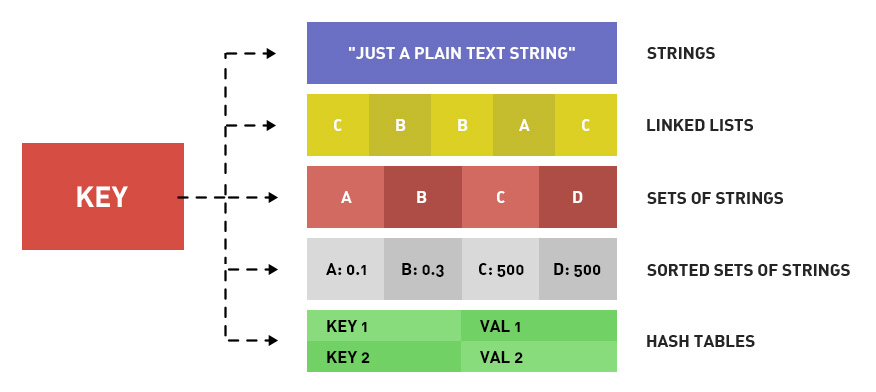
โดยปกติข้อมูลที่เก็บใน Redis จะมี Data model แบบ Key-value
ซึ่ง value สามารถมีรูปแบบของข้อมูลหลัก ๆ ดังนี้
- Primitive data type เช่น string และ number
- Data structure ประกอบไปด้วย List, Set, Hash, SortedSet เป็นต้น
โดยส่วนใหญ่เราจำเป็นต้องทำความเข้าใจว่า
ระบบงานของเรานั้น ต้องการใช้ข้อมูลอย่างไร
เพื่อให้เลือก data structure ได้อย่างเหมาะสม
เนื่องจากการเข้าถึงข้อมูลใน Redis นั้น
จะมีการบอกและอธิบายไว้ชัดเจนว่ามี Big O เท่าไร
ยกตัวอย่างเช่น การทำงานของ SORT operation
จะมี Big O คือ O(N+M*(log M)) นั่นคือ
มีการทำงานตามจำนวนข้อมูลเป็นอย่างต่ำ

ดังนั้นจะดีกว่าไหม ถ้าเราลดเวลาการทำงานลงไป
ด้วยการเก็บข้อมูลที่ไม่ต้องมา SORT แบบนี้
หรือเป็นการเก็บข้อมูลแบบที่ SORT ให้เลยตั้งแต่แรก
นั่นคือการใช้ SortedSet
จากนั้นดึงข้อมูลก็ใช้ ZRANGE operation
ที่มี Big O เพียง O(M*(log M))
ซึ่งน่าจะงานได้มีประสิทธิภาพกว่าไหม ?

ดังนั้นเรื่องของการออกแบบ ต้อง สัมพันธ์การ use case ของระบบ
ไม่ใช่เพียงแค่เก็บในสิ่งที่ทำงานได้รวดเร็วเท่านั้น
เพราะว่า แทนที่จะทำงานได้เร็ว กลับกลายเป็นคอขวด
เพราะว่าจะเก็บอย่างเดียว
โดยไม่ได้สนใจการนำมาใช้งาน ว่ามี operation cost มากเพียงใด