อ่านบทความเรื่อง Data Lake จาก bliki ของคุณ Martin Fowler
จึงนำมาแปลกันเล็กน้อย เพื่อทำให้ตัวเองเข้าใจว่า
- Data Lake มันคืออะไรกันแน่ ?
- มันแตกต่างจาก Data Warehouse และ Data Mart อย่างไร ?
มาดูกันดีกว่า
คำว่า Data Lake เกิดขึ้นมา
เพื่อใช้อธิบายส่วนการทำงานที่สำคัญ
สำหรับขั้นตอนการวิเคราะห์ข้อมูลในโลกของ Big Data
โดยมีแนวความคิดหนึงก็คือ ให้ทำการจัดเก็บข้อมูลดิบ (Raw data) ไว้เพียงที่เดียว
เป็นที่ๆ ใครก็ตามสามารถนำข้อมูลดิบเหล่านี้ไปใช้งาน และ วิเคราะห์ต่อไปได้
และแน่นอนว่า Data Lake มันต้องมีขนาดใหญ่อย่างแน่นอน
ทำให้ในส่วนนี้คนมักจะนำ Hadoop มาสร้าง
แต่แนวคิดของ Data Lake มันมีมากกว่า Hadoop นะครับ
ดังนั้นมาดูกันต่อไป
แต่เมื่อมีการพูดถึงที่จัดเก็บข้อมูลใหญ่ๆ เพียงที่เดียว
เพื่อใช้สำหรับการวิเคราะห์แล้ว ต้องคิดถึง Data Warehouse และ Data Mart อย่างแน่นอน
ดังนั้น คำถามที่เกิดขึ้นมาก็คือ
แล้ว Data Lake แตกต่างอย่างไรล่ะ ?
Data Lake นั้นทำการเก็บข้อมูลดิบจากแหล่งข้อมูลต่างๆ
Data Lake นั้นไม่มีการกำหนด หรือ สรุปโครงสร้างข้อมูลที่จัดเก็บ
โดยรูปแบบข้อมูลที่จัดเก็บ ก็ขึ้นอยู่กับแหล่งที่มานั้นๆ
หรืออาจจะเรียกว่า Schemaless ก็ได้
ดังนั้น ผู้ใช้งานข้อมูลจาก Data Lake
จำเป็นต้องมีขั้นตอนการนำข้อมูลไปจัดการก่อนทำการวิเคราะห์ต่อไป
ส่วน Data Warehouse นั้นจะแตกต่างออกไป
เพราะว่า ต้องทำการสร้างเพียง schema เดียว
สำหรับการวิเคราะห์ทุกๆ อย่าง ซึ่งเป็นเรื่องที่ยากลำบากมากๆ
หรืออาจจะใช้เวลานานในการเริ่มต้นระบบ
สิ่งที่เน้นคือ คำว่าคุณภาพของข้อมูลที่จัดเก็บ
และสิ่งที่ต้องทำการออกแบบคือ Data model
ส่วนคนที่ทำการวิเคราะห์คือตำแหน่ง Data analyst
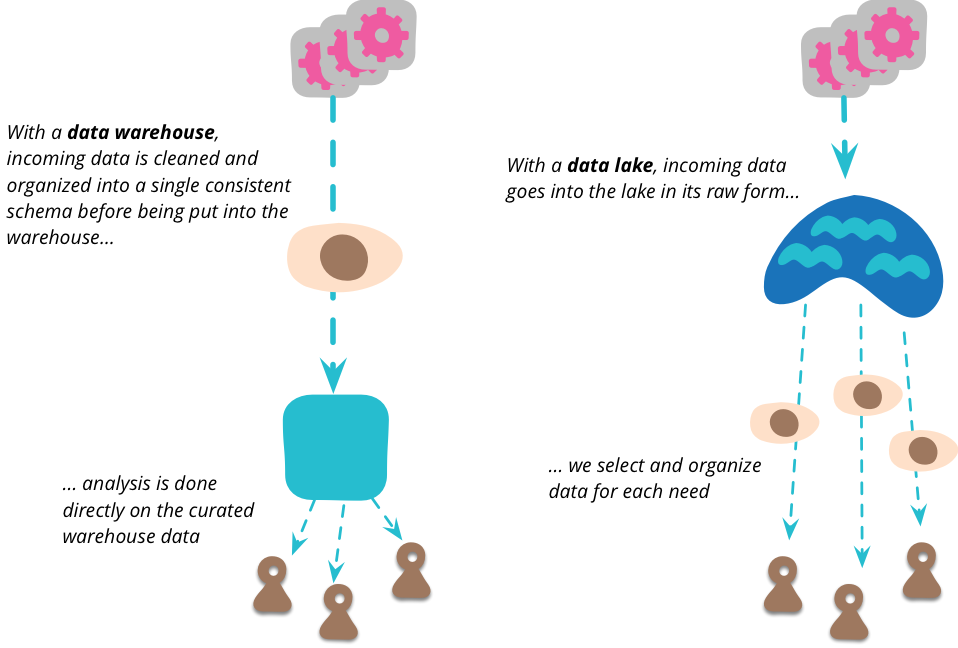
รูปแสดงความแตกต่างระหว่าง Data Warehouse กับ Data Lake
ในปัจจุบันตำแหน่งยอดนิยมในโลกของการวิเคราะห์ข้อมูลคือ Data Scientist
และพบมากด้วยว่าชอบใช้ชื่อนี้ ในทางหรือความหมายที่ผิดๆ
แน่นอนว่า ตำแหน่งนี้ต้องมีพื้นฐานความรู้มากจากวิทยาศาตร์
ซึ่งนักวิทยาศาตร์นั้นให้ความสำคัญกับปัญหาคุณภาพของข้อมูลอย่างมาก
ตัวอย่างเช่น
ถ้าคุณทำการวิเคราะห์ข้อมูลอุณหภูมิของอากาศ
เพื่อพยากรณ์ หรือ บอกสภาพอากาศในแต่ละวันว่าเป็นอย่างไร
แต่ถ้าระบบคุณมีปัญหาเรื่องตัวเก็บข้อมูล
ที่อาจจะมีปัญหาในเก็บข้อมูลในบางช่วงเวลา
ทำให้การอ่านข้อมูล และ วิเคราะห์ข้อมูลมีปัญหาขึ้นมา
ดังนั้นสิ่งที่นักวิทยาศาตร์ต้องทำก็คือ
การนำเทคนิคทางด้านสถิติเข้ามาช่วยในการแก้ไขปัญหาของข้อมูล
เพื่อทำให้เรายังสามารถทำการวิเคราะห์ข้อมูลได้
และช่วยแก้ไข หรือ บรรเทาปัญหาที่เกิดจากข้อมูลลงไป
แต่ข้อมูลที่จะเอาใช้ในการแก้ไขปัญหาเรื่องคุณภาพของข้อมูลนั้น
จะนำมาจากไหนล่ะ ?
ถ้าไม่ใช่นำข้อมูลดิบมาทำการวิเคราะห์
และแก้ไขด้วยเทคนิคทางด้านสถิติต่อไป
ดังนั้น ข้อมูลดิบจึงมีความสำคัญมากกว่า ข้อมูลที่ทำการกลั่นกรองออกมาแล้ว
และในบางครั้งข้อมูลที่ถูกกลั่นกรองมานั้น อาจจะทำให้เกิดปัญหาได้อีกด้วย
ปัญหาของ Data Lake คืออะไรล่ะ ?
ข้อมูลที่จัดเก็บคือ ข้อมูลดิบ
นั่นแสดงว่า เป็นข้อมูลที่ซับซ้อน
ดังนั้น เราจึงต้องการการจัดการเพื่อทำให้โครงสร้างข้อมูลมันง่าย
รวมทั้งยังช่วยลดขนาดข้อมูลลงไปอีกด้วย
แต่เราไม่สามารถเข้าถึงข้อมูลใน Data Lake บ่อยๆ ไม่ได้หรอกนะ
เพราะว่า มันซับซ้อน ต้องใช้ความสามารถเยอะๆ
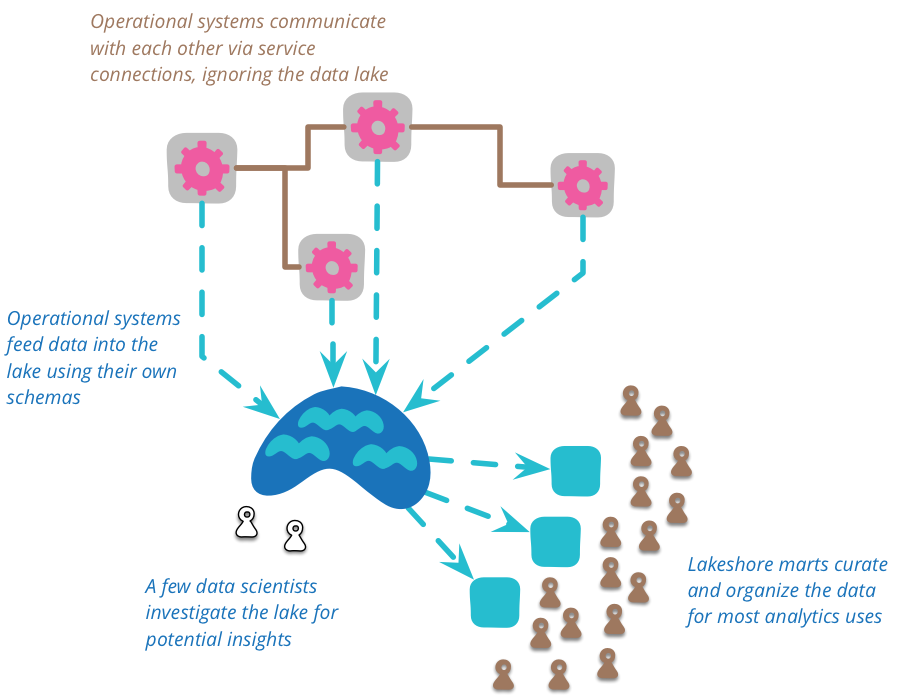
ดังนั้น เราจำเป็นต้องการผู้เชี่ยวชาญเข้ามา
สร้าง view ของข้อมูลจาก Data Lake เพื่อให้ใช้งานที่แต่ละส่วนไป
ซึ่งในบทความจะเรียกว่า Lakeshore mart
เพื่อให้แต่ละทีมในองค์กรนำไปใช้วิเคราะห์ต่อไปได้ง่าย
แสดงดังรูป
สุดท้ายแล้ว
น่าจะพอทำให้เห็น และ เข้าใจบ้างว่า Data Lake มันคืออะไร
แตกต่างจาก Data Warehouse อย่างไร
รวมถึงแนวคิดต่างๆ ก่อนนำข้อมูลเหล่านั้นมาทำการวิเคราะห์
และแน่นอนว่า คำถามสุดฮิตจาก Data Lake
คือเรื่อง Security และ Privacy ของข้อมูล
เนื่องจากเรามีข้อมูลดิบทั้งหมดเลย ใครๆ ก็หมายปองที่จะนำข้อมูลเหล่านี้ไปใช้งาน
ดังนั้น การเข้าถึง Data Lake ควรกำหนดให้เข้าเพียงกลุ่มคนที่จำเป็นเท่านั้น
เพื่อลดปัญหาที่จะเกิดขึ้นตามมา