จากการแบ่งปันเรื่องปัญหาของระบบที่ทำงานช้า
เมื่อพูดคุย วาดรูปของ architecture ของระบบแล้ว
ได้เห็นว่า ต้นเหตุของปัญหาหลัก ๆ คือ
เรื่องการการจัดการข้อมูล นั่นคือ
- ปัญหาในการแก้ไขข้อมูลทั้งการเขียน แก้ไขและลบ
- ปัญหาในการอ่านข้อมูล
มักจะแก้ไขข้อมูลโดยไม่คำนึงถึงการใช้งาน เช่นการ ดึงข้อมูลเลย
เก็บ ๆ กันไปก่อน แล้วค่อยไปดึงการทีหลัง !!
ยกตัวอย่างเช่น
ในการบันทึกข้อมูลจะกระจายข้อมูลไปยัง table ต่าง ๆ ของ RDBMS
แต่เมื่อต้องอ่านข้อมูล จำเป็นต้อง join กันใน table จำนวนมาก
ผลคือ เมื่อระบบมีข้อมูลมากขึ้น มีผู้ใช้งานสูงขึ้น
ส่งผลให้ระบบทำงานช้าลงไปอย่างมาก !!
เราควรแก้ไขปัญหาเช่นนี้อย่างไรบ้าง ?
จึงเป็นที่มาของการอธิบายแนวคิดของ CQRS (Command-Query Responsibility Separation)
แบบคร่าว ๆ นิดหน่อย
เพื่อให้เห็นแนวทางหนึ่งในการแก้ไขแบบง่าย ๆ
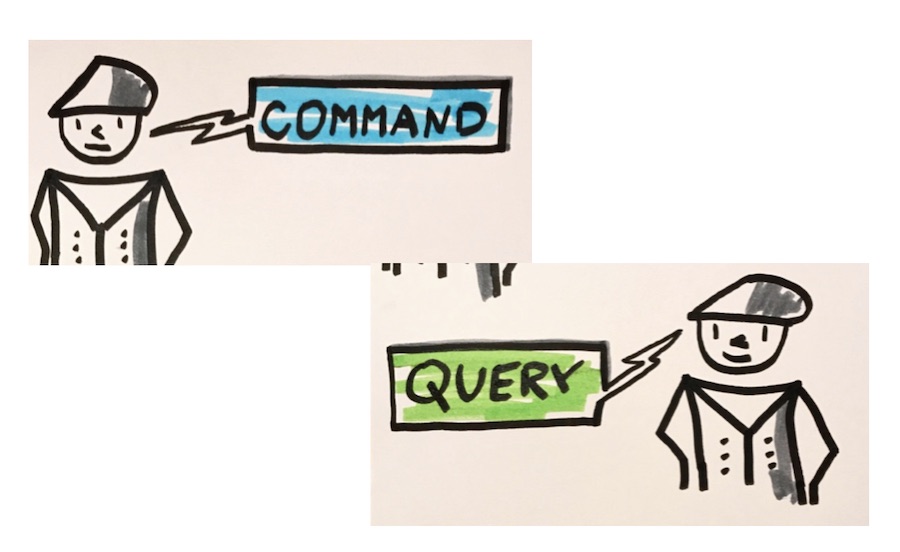
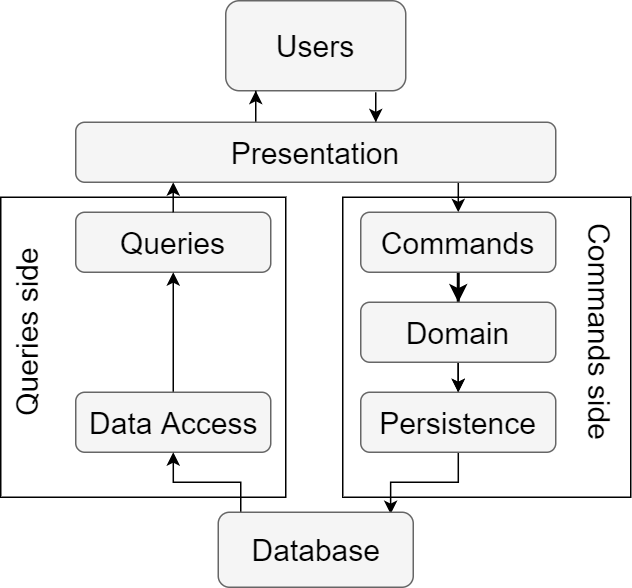
หัวใจหลักของ CQRS คือ
การแยกกันออกแบบและทำงานระหว่าง
การแก้ไขข้อมูล (Command operation)
และการอ่านข้อมูล (Query operation)
แน่นอนว่า ทั้งสองส่วนมีการทำงานที่แตกต่างกัน
ดังนั้นการออกแบบและพัฒนาน่าจะต่างกัน
ทั้งเรื่องของ entity ของข้อมูล
ทั้งเรื่องของ Database model ที่ใช้งานทั้ง Relational และ NoSQL
ทั้งเรื่องของ Database server ที่อาจจะต้องแยกกันหรือไม่
ทั้งเรื่องของระบบที่รองรับก็ต้องแยกกันหรือไม่
แต่ปัญหาที่ตามมาคือ ความซับซ้อนของระบบที่สูงขึ้น
การพัฒนาและดูแลที่ยากขึ้น หรือมี operation สูงขึ้น
ใน CQRS นั้นก็มีโครงสร้างการทำงานหลาย ๆ แบบ
แต่มีรูปแบบที่ใช้งานบ่อย ๆ 3 แบบดังนี้
แบบที่ 1 ใช้งาน Database เดียวกัน
เป็นรูปแบบของ CQRS ที่เรียบง่ายที่สุด
คือแยกการทำงานใน code ออกจากกัน
ยกตัวอย่างเช่น
การแก้ไขข้อมูลอาจจะใช้ ORM framework เช่น JPA หรือ Hibernate เป็นต้น
ส่วนฝั่งการอ่านข้อมูลใช้งานผ่าน SQL ตรง ๆ ไปเลย
แสดงดังรูป
https://levelup.gitconnected.com/3-cqrs-architectures-that-every-software-architect-should-know-a7f69aae8b6c
แบบที่ 2 แยก database ออกจากกัน
แต่เมื่อมีการแก้ไขข้อมูลแล้ว
จะต้องทำการบันทึกการเปลี่ยนแปลงนั้น ๆ
ไปยัง database ของการอ่านข้อมูลเสมอ
แสดงดังรูป
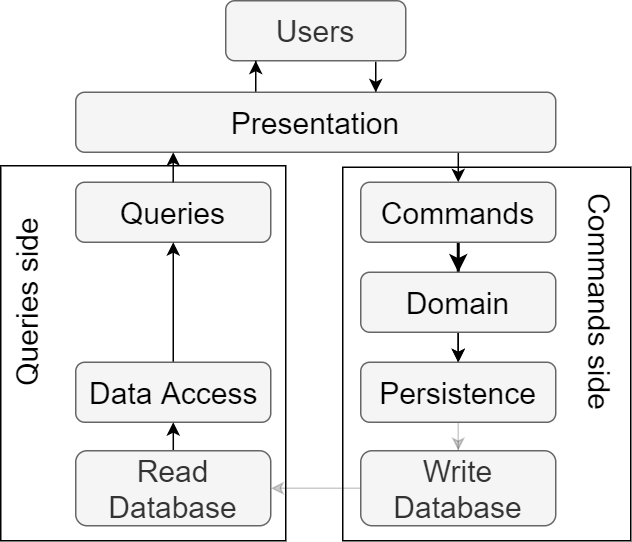
https://levelup.gitconnected.com/3-cqrs-architectures-that-every-software-architect-should-know-a7f69aae8b6c
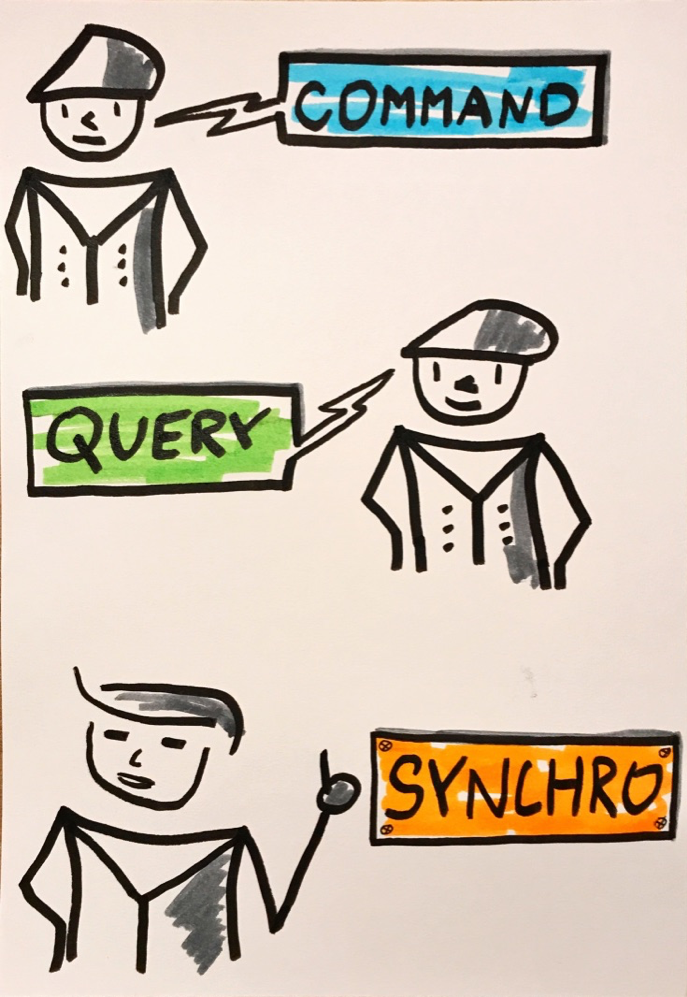
แบบที่ 3 แยก database เช่นกัน แต่นำ Event Sourcing มาช่วยในการ sync ข้อมูล
โดยการ sync ข้อมูลนั้น จะไม่ได้เป็นแบบ synchronous หรือทันที
จะป็นแบบ asynchronous หรือในเรื่องของ consistency
จะเรียกว่า Eventual Consistency นั่นเอง
เพื่อปรับปรุงประสิทธิภาพการทำงานของแบบที่ 2
แสดงดังรูป
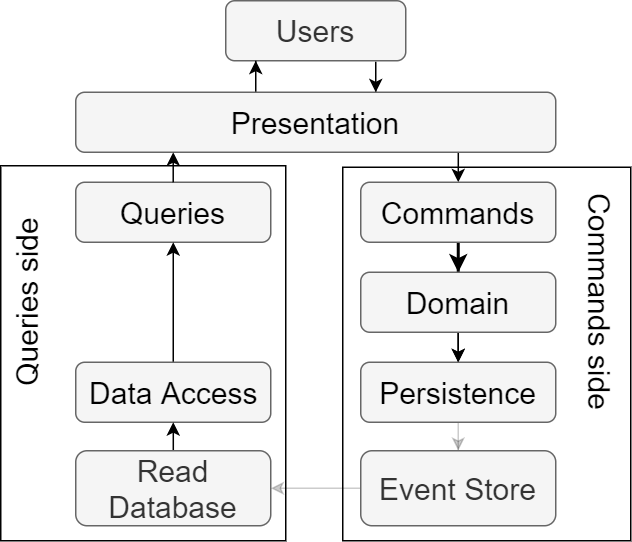
https://levelup.gitconnected.com/3-cqrs-architectures-that-every-software-architect-should-know-a7f69aae8b6c
ปล. ทุกแนวทางมีทั้งข้อดีและข้อเสีย
ดังนั้นควรเข้าใจก่อนการเลือก
รวมทั้งเลือกวิธีการให้เหมาะสมกับปัญหารวมทั้งความรู้ความสามารถในการจัดการด้วย