หลังจากอธิบายเกี่ยวกับ Model database สำหรับจัดการ Big Data ไปแล้ว
รวมทั้งการติดตั้ง Riak ด้วย Docker
แต่สิ่งที่เรายังไม่รู้เลยก็คือ
- Riak มันคืออะไร
- ทำไมต้องศึกษา Riak ด้วยล่ะ
- เข้ามาจัดการ Big Data อย่างไร
ดังนั้น มาเริ่มต้นดูกันเลยดีกว่า
Riak คืออะไร
Distributed database หรือ ฐานข้อมูลแบบกระจาย
ได้รับแรงบันดาลใจจาก Amazon Dymamo
จัดเก็บข้อมูลในรูปแบบ Key-value
มีสถาปัตยกรรมที่รองรับเรื่อง
- Availability คือ พร้อมใช้งานอยู่เสมอ เนื่องจากมีการทำ replicate ดังนั้นจึงพร้อมสำหรับการอ่าน เขียน เสมอ
- Fault tolerance คือ สามารถทำงานต่อไปได้ ในสภาวะที่มีความเสียหายต่างๆ เกิดขึ้น นั่นคือ มีความคงทนนั่นเอง
- Scalability คือ รองรับการขยายตัวของระบบได้
- การจัดการที่ง่าย เช่น การเพิ่มหรือลด node เป็นต้น
โดยแต่ละ node ของ Riak สามารถเป็น master node ได้ทั้งหมด ซึ่งคุณลักษณะนี้ว่า masterless
แต่ละ node จะทำการ replicate ข้อมูลกันไว้ ดังนั้น ถ้ามี node ใดๆ ล่มลงไปแล้ว
ระบบของ Riak ยังคงสามารถทำการอ่าน เขียน ลบ และแก้ไขข้อมูลได้
มาดูในแง่เทคนิคของ Riakกันหน่อย
1. ในแง่ของการ Scale ระบบ
มีการเก็บข้อมูลในฐานข้อมูลหลายๆ ที่ เพื่อรองรับจำนวนข้อมูลที่เพิ่มมากขึ้น
โดยวิธีการนี้เรียกว่า Sharding
ตัวอย่างเช่น
- การเก็บข้อมูลในฐานข้อมูลโดยแยกตามทวีป
- การเก็บข้อมูลในฐานข้อมูลโดยแยกตามตัวอักษร หรือ ตัวเลข
สามารถทำการแยกข้อมูลตามความต้องการทางธุรกิจ
โดยไม่ทำให้ประสิทธิภาพการทำงานลดลง
และสามารถทำการ rebalance ข้อมูลใน shard ต่างๆ เมื่อเพิ่ม node เข้าไป
ซึ่งสามารถทำได้ไม่ยากนัก มันทำให้ operation การจัดการง่ายขึ้น
ซึ่งมันตอบรับกับ Big Data, การขยายตัวของระบบอย่างรวดเร็ว และ จำนวน traffic ที่สูงขึ้น
ข้อมูลต่างๆ ที่ถูกจัดเก็บใน Riak จะถูกกระจายไปในทุกๆ node ด้วย Hashing function
ถ้ามีการเพิ่ม node เข้าไปใหม่ ก็จะทำการกระจายไปให้โดยอัตโนมัติ
ทำให้ไม่เกิดปัญหา Hot Spot ไปยัง node ใด node หนึ่ง ( นั่นคือมีข้อมูลเขียน node ใด node หนึ่งมากเกินไป )
2. Data model
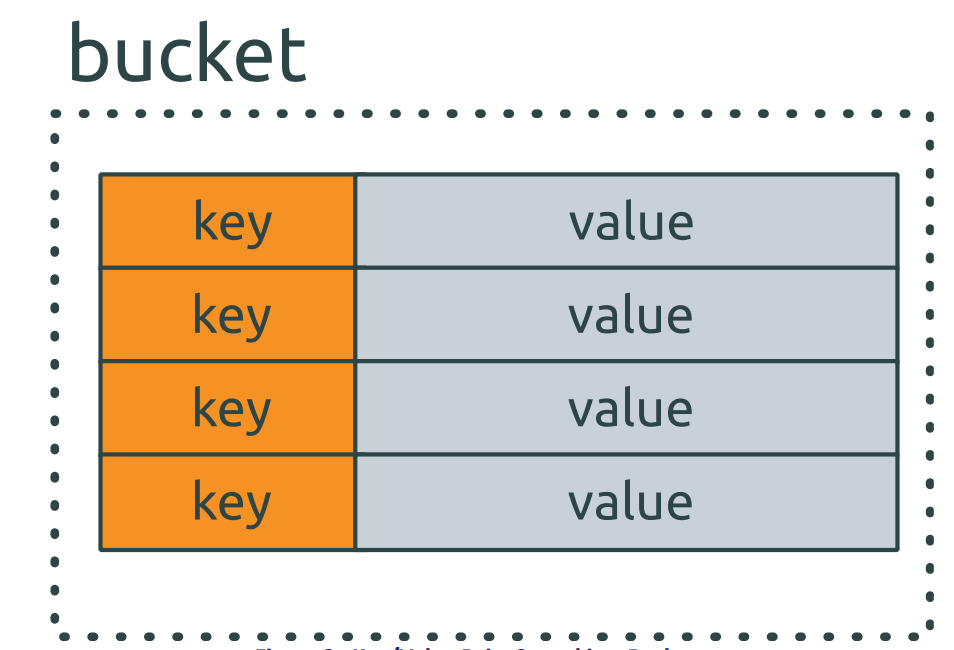
รูปแบบการเก็บข้อมูลเป็นแบบ key-value เรียกว่า object
โดยแบ่งแยกตามกลุ่มเรียกว่า bucket
ข้อมูลที่จัดเก็บลงไปนั้นมีชนิดเดียวก็คือ binary เท่านั้น
ดังนั้น ในการเก็บจะใช้ hash function ด้วย key และ bucket ดังรูป
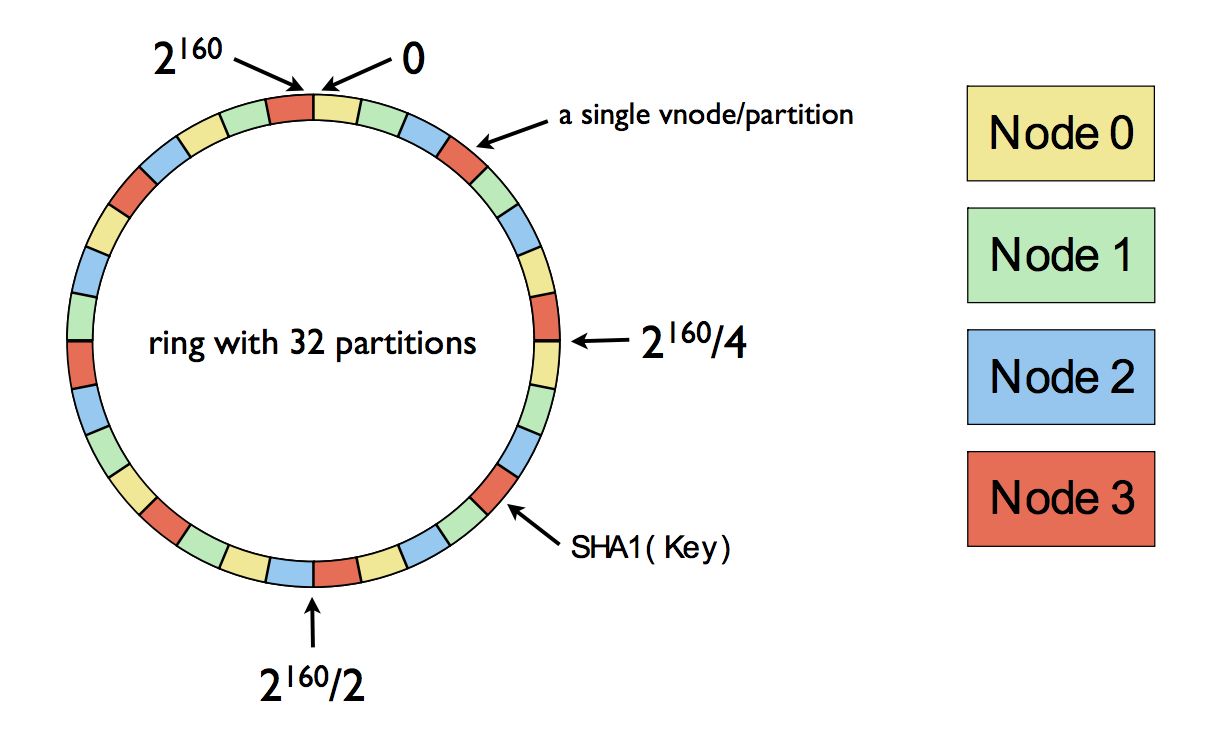
ส่วน value หรือข้อมูล จะถูก mapping อยู่ใน integer space ขนาด 160 bit
ซึ่ง integer space จะถูกจัดการอยู่ในรูปแบบของวงแหวน (ring)
เพื่อระบุว่าข้อมูลจะถูกจัดเก็บใน node หรือ เครื่องไหน
โดยในวงแหวนจะมีการแบ่งออกเป็น partition ซึ่งเริ่มต้นมีจำนวน 64 partition
แต่ละ partition จะมี virtual node (vnode) จัดการหรือดูแล
เพื่อทำการจับคู่กับ server หรือ node จริงๆ ต่อไป ดังรูป
ข้อควรรู้ก่อนใช้งาน Riak
ก่อนจะนำไปใช้งาน ต้องเข้าใจก่อนว่า Riak มันก็มีทั้งข้อดีและข้อเสีย
ดังนั้นจำเป็นต้องรู้และเข้าใจ ก่อนตัดสินใจลงทุน เพราะว่าการลงทุนมีความเสี่ยง..
1. เริ่มด้วยเรื่อง Eventually Consistency
นั่นคือข้อมูลจะถูกต้อง หลังจากผ่านไปช่วงเวลาหนึ่ง (Eventually)
เนื่องจากการทำงานของระบบแบบกระจายนั้น เรื่อง ที่ไม่คาดหวังมันคือ สิ่งที่คาดหวัง เสมอ
นั่นหมายความว่า แต่ละ node มันสามารถที่จะถูกเพิ่ม ลบ ออกไปจาก cluster ได้เสมอ
ไม่ว่าจะมาจาก node พัง หรือ คนดูแลระบบเพิ่ม node ใหม่เข้ามา
อาจจะทำให้หลายๆ node ไม่สามารถทำงานได้
แต่ระบบยังคงสามารถอ่าน และ เขียนข้อมูลได้เช่นเดิม
ดังนั้น ระบบคาดหวังว่าแต่ละ node จะต้องมีข้อมูลที่เหมือนกัน
เมื่อผ่านช่วงเวลาหนึ่งๆ นั่นคือไม่ทันทีนะ
2. เรื่องของ Data model
เนื่องจากรูปแบบการเก็บข้อมูลของ Riak เป็นแบบ Key-value
ซึ่งมันยึดหยุ่น ทำงานได้รวดเร็ว
แต่มันก็มีข้อเสียหรือข้อจำกัดเช่นกัน
ตัวอย่างเช่นไม่สนับสนุนเรื่อง set, counter, transaction และการ join
ส่วนข้อดีของมันที่เพิ่มเข้ามา เช่น
- การค้นหา ซึ่งสนับสนุน full-text search
- สนับสนุน Map-Reduce
ก่อนที่จะเลือกอะไรก็ตามมาจัดการข้อมูล จำเป็นต้องตอบคำถาม 3 ข้อ
- ขนาดของข้อมูลของคุณว่าเป็นเท่าไร
- ข้อมูลของคุณถูกจัดเก็บในรูปแบบใด
- ข้อมูลของคุณมีความสำคัญมากน้อยเพียงใด
โดย Riak อาจจะเป็นตัวเลือก ถ้าคุณตอบในรูปแบบนี้
- ข้อมูลมีขนาดอยู่ในระดับ Terabyte (TB) ?
- ข้อมูลของคุณมีหลายรูปแบบเหลือเกิน ?
- ข้อมูลมีความสำคัญ ห้ามหายโดยเด็ดขาด สามารถใช้งานได้เสมอ ?
แล้วระบบแบบไหนบ้างที่เขานำ Riak ไปใช้งานกันบ้าง
1. Digital media
ตัวอย่างเช่นระบบการโฆษณา ที่ต้องรับ request ต่างๆ มาเพื่อบริการโฆษณาจำนวนมาก
และการตอบสนองหรือการส่งพวกโหษณากลับไปยังผู้ร้องขอต้องรวดเร็วด้วย
ดังนั้น ถ้าต้องการให้ระบบฐานข้อมูลแบบเดิมสนับสนุนกสนใช้งานแบบนี้
คงต้องทำการ configuration มากมาย และ แพง
ดังนั้นการขยายระบบในแนวนอนดังเช่น Riak น่าจะเป้นทางเลือกที่ดูดีทางหนึ่ง
2. E-commerce
บริษัทที่ให้บริการ E-commerce ต้องการให้ระบบสามารถทำงานได้ตลอดเวลา
เพื่อรองรับผู้ใช้งาน และถ้าเกิดลูกค้าเจอประสบการณ์ที่ไม่ดีกับระบบแล้ว
ก็อาจจะทำให้เสียลูกค้าไปทันที และทำให้สูญเสียรายได้ไปด้วย
ดังนั้น Riak จึงเข้ามาช่วยแก้ปัญหาในเรื่องนี้ได้โดยตรง
เช่น ระบบ shopping cart เป็นต้น
3. Game
ระบบของเกมส์มักจะเก็บข้อมูลต่างๆ ไว้ใน server เช่น
- ข้อมูลต่างๆ ของผุ้เล่น
- สถิติต่างๆ ของผู้เล่นแต่ละคน
- อันดับของผู้เล่น
- เก็บ Session ของผุ้
- เก็บข้อมูลเกี่ยวกับความสัมพันธ์ของผู้ใช้งานต่างๆ ของระบบ ในรูปแบบ Social
- เก็บข้อมูลรูปภาพ และ วิดีโอ
- เก็บข้อมูลที่มาจาก Sensor ของอุปกรณ์ต่างๆ
- เก็บข่อมูลในรูปแบบ Text, XML, JSON, HTML
โดยมีการเรียกใช้งานที่สูงมากๆ บางครั้งเป็นแบบ realtime
ข้อมูลต่างๆ จะเพิ่มจำนวนขึ้นอย่างรวดเร็ว ทั้ง ข้อความ รูป และ วิดีโอ
ส่งผลให้ระบบต้องสามารถรองรับการขยายระบบแบบแนวนอนด้วย
และต้องทำได้ง่าย ซึ่ง Riak ก็สามารถตอบโจทย์นี้ได้เช่นกัน
สามารถดูกรณีจากบริษัทเกมส์ต่างๆ ว่านำ Riak ไปใช้แล้วเป็นอย่างไร ที่นี่
ตัวอย่างการใช้งาน Riak เพิ่มเติมครับ => Riak Use Case
โดยสรุป
ดังนั้น ถ้าฐานข้อมูลของคุณเกิดปัญหาคอขวดขึ้นมาแล้ว
ลองเปลี่ยนวิธีการขยายระบบจากแบบแนวตั้ง คือ การเพิ่ม CPU, Memory, Harddisk
มาเป็นแบบแนวนอน คือ การเพิ่ม node การทำงานเข้ามาช่วยกันทำงาน
ซึ่งถ้าคุณเลือกแบบแนวนอนแล้ว Riak ก็เป็นอีกหนึ่งทางเลือกครับ