จากบทความเรื่อง Model everything to fail fast
ทำการอธิบายเกี่ยวกับ
การออกแบบ workflow สำหรับ Fail Fast ได้อย่างน่าสนใจ
ทุก ๆ ครั้งที่ทีมพัฒนาทำการแก้ไขสิ่งต่าง ๆ
ไม่ว่าจะเป็น code
ไม่ว่าจะเป็น database
ไม่ว่าจะเป็น automated testing
ไม่ว่าจะเป็น infrastructure
ไม่ว่าจะเป็น deployment script
ไม่ว่าจะเป็น configuration file
เราต้องใช้เวลานานเท่าไร กว่าจะรู้ว่าสิ่งที่แก้ไขไปนั้นมันถูก หรือ ผิด ?
เมื่อทำการแก้ไขแล้ว
ต้องทำการตรวจสอบว่าการแก้ไขเหล่านั้น
มันไม่ส่งผลกระทบใด ๆ ต่อระบบทั้งหมดหรือไม่
มันทำให้ระบบทำงานผิดพลาดหรือไม่
ต้องรู้ให้เร็วที่สุดเท่าที่จะเป็นไปได้
เพื่อทำให้เรามั่นใจ และ เชื่อมั่นต่อระบบ
สิ่งที่ทีมพัฒนาต้องการคือ การพัฒนาให้เร็วที่สุดเท่าที่จะทำได้
ดังนั้น สิ่งที่ต้องมีด้วยเสมอ คือ Fail Fast
หรือให้รู้ว่าสิ่งที่แก้ไขไปนั้น มันทำให้เกิดปัญหา เร็วที่สุด
คำถาม
ลองกลับไปดูสิว่า ทีมพัฒนาของคุณใช้เวลาเท่าไร ?
กว่าจะรู้ว่า แต่ละการเปลี่ยนแปลงมันกระทบต่อระบบ
เมื่อเรารู้ว่ามีปัญหาได้อย่างรวดเร็ว
เราก็สามารถทำการแก้ไขได้อย่างรวดเร็วเช่นกัน
และเราจะพัฒนา และเดินไปข้างหน้าได้อย่างรวดเร็ว
มาดูว่า จากบทความอธิบาย Workflow ของ Fail Fast ไว้อย่างไร ?
Model พื้นฐาน คือ Build-Test-Release
แสดงการทำงานดังรูป
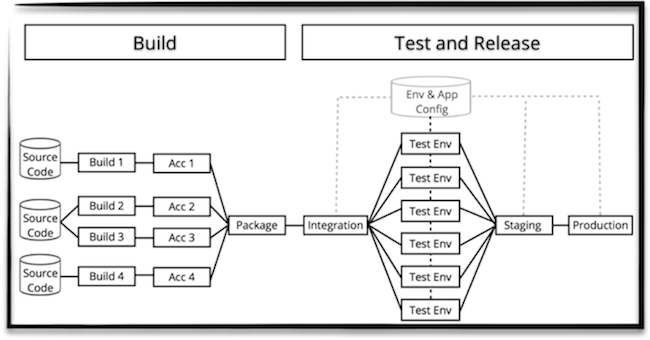
คำอธิบาย
- เมื่อ source code มีการเปลี่ยนแปลง จะทำการ build ทันที
- ผลลัพธ์ที่ได้คือ packaging ของระบบที่พร้อม deploy เช่น WAR, EAR หรือ executable file เป็นต้น
- จากนั้นทำการ deploy ไปยัง dev/test environment เพื่อทำการทดสอบ เรียกว่า integration test
- เมื่อผลการทำสอบผ่าน จะทำการ deploy ไปยัง staging และ production server
แน่นอนว่า ทั้ง workflow นั้นต้องทำงานแบบอัตโนมัตินะสิ
แต่ถ้าเราต้องการ Feedback ที่รวดเร็วขึ้น
จะต้องทำดังนี้เพิ่มเติม
- ขั้นตอนแรก ๆ ใน workflow ควรเป็นงานที่มีความสำคัญมาก ๆ เสมอ
- แต่ละส่วนของ workflow ต้องทำงานแบบขนาน หรือ ทำงานพร้อม ๆ กันได้
เราต้องรู้ว่า แต่ละขั้นตอนใน workflow มีการทำงานอย่างไร ?
เพื่อตอบปัญหาต่าง ๆ เหล่านี้
- Code ส่วนไหนที่ก่อให้เกิดปัญหา เช่น commit หมายเลขอะไร การเปลี่ยนแปลงอะไร ?
- Dependency อะไรที่ก่อให้เกิดปัญหา ?
- ในแต่ละ build มีการทำงานอะไรที่แตกต่างกันบ้าง ?
- ในแต่ละ release มี feature และ แก้ไข bug อะไรบ้าง ?
- เลข version ของ software ในแต่ละ environment คืออะไร ?
- ใครบ้างที่ทำการ deploy ?
ดังนั้น เครื่องมือที่นำมาใช้ในการสร้าง
ต้องช่วยเหลือเรื่องต่าง ๆ เหล่านี้ด้วยนะ
เพื่อทำให้เรามองเห็นปัญหาได้ง่าย (Visibility)
และช่วยเหลือเรื่องการติดตามการทำงานอีกด้วย
นี่คือทฤษฎี และ แนวทางสำหรับการสร้าง workflow สำหรับ Fail Fast
มาดูกันว่า ถ้าในการทำงานจริง ๆ จะออกแบบอย่างไร ?
ตัวอย่างเช่น
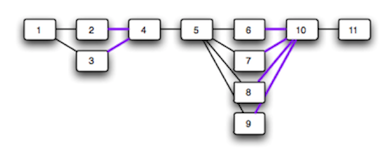
workflow ของการ Build-Test-Release ของระบบมี 11 ขั้นตอน
และทำงานตามลำดับจาก 1 ถึง 11 ดังรูป

เราสามารถทำการแก้ไข หรือ ปรับปรุงให้เร็วขึ้นได้
โดยปรับให้บางขั้นตอนทำงานแบบขนานไปเลย
แต่ต้องดูด้วยนะว่า
มันสามารถทำงานแบบขนานได้จริง ๆ
แสดงดังรูป
หรือการทำงานบนเครื่องเดียวมันช้า
แนะนำให้กระจายการทำงานไปยังเครื่องต่าง ๆ
เช่นการทดสอบระบบ
สามารถใช้ Distribute testing ได้
แสดงดังรูป
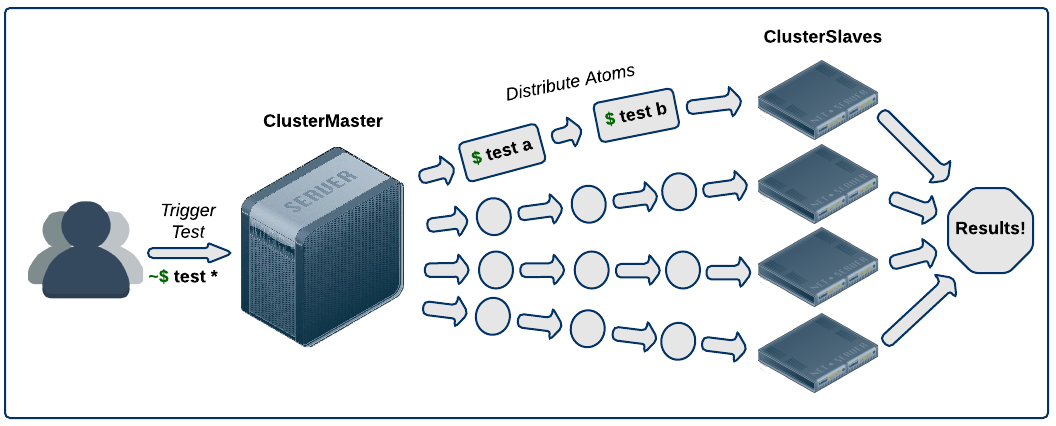
เพียงเท่านี้ก็สามารถสร้างระบบ Build-Test-Release
ที่มี feedback loop ที่รวดเร็ว
นั่นคือเป็น workflow ที่รองรับเรื่อง Fail Fast นั่นเองครับ
ดังนั้น อย่ากลัวเรื่องของ Fail
ตราบใดที่เราสามารถรู้ว่ามัน Fail ได้อย่างรวดเร็ว
หรือรู้ก่อนผู้ใช้งาน !!!
คำถามสุดท้าย
Workflow ของการ Build-Test-Release ของคุณนั้น
มี feedback loop ที่รวดเร็วหรือไม่ ?
ถ้าตอบว่า ช้า
และ ไม่มีใครที่มองเห็น และ เข้าใจมันเลย
ยกเว้นคนติดตั้ง หรือ ดูแลระบบ
และ ไม่สามารถ trace อะไรได้เลย
แสดงว่า คุณกำลังเดินผิดทางแล้วนะครับ
เมื่อพูดถึง Fail Fast ผมนึกถึงรูปนี้เสมอ