ช่วงปลายปีมีโอกาสไปสอนและแบ่งปันความรู้
เรื่อง ELK stack สำหรับ Big Data Analytic เป็นเวลา 3 วัน
ที่สำนักวิทยบริการ มหาวิทยาลัยราชภัฏยะลา
โดยครั้งนี้มีเวลา 3 วัน จึงทำให้ได้เนื้อหาที่เข้มข้นและลงรายละเอียดเยอะ
เลยทำการสรุปไว้นิดหน่อย
ไว้ปีหน้าหาเวลามาแบ่งปันกันนิดหน่อย
เนื่องจาก ELK stack มันเปลี่ยนบ่อยเหลือเกิน
มาเริ่มกันเลย
เป้าหมายของการสอนและแบ่งปันครั้งนี้
ปูพื้นฐานให้เข้าใจตัว ELK stack ซึ่งประกอบไปด้วย
- Elasticsearch สำหรับจัดเก็บข้อมูล
- Log stash สำหรับนำเข้าและ transform ข้อมูลให้อยู่ในรูปแบบที่ต้องการ สามารถนำมาสร้างเป็น data pipeline ได้
- Kibana สำหรับ visualize ข้อมูลในรูปแบบต่าง ๆ เพื่อทำให้เข้าใจข้อมูล รวมทั้งมีเครื่องมือต่าง ๆ อีกเพียบ ทั้ง dev tool, monitoring เป็นต้น
แต่ในปัจจุบันก็มี project ที่ชื่อ Beats ขึ้นมา
ทำหน้าที่คล้ายกับ Log stash นั่นเอง แต่มีความเฉพาะเจาะจงอย่างมาก
รวมทั้งไม่มีส่วนของการ transform ข้อมูล
มีเพียง input และ output เท่านั้น
ทำให้ทำงานเร็ว และ ใช้ resource ที่น้อยลง
เหมาะกับการเป็น Agent ไปทำงานในแต่ละเครื่องมากกว่า Log stash นั่นเอง
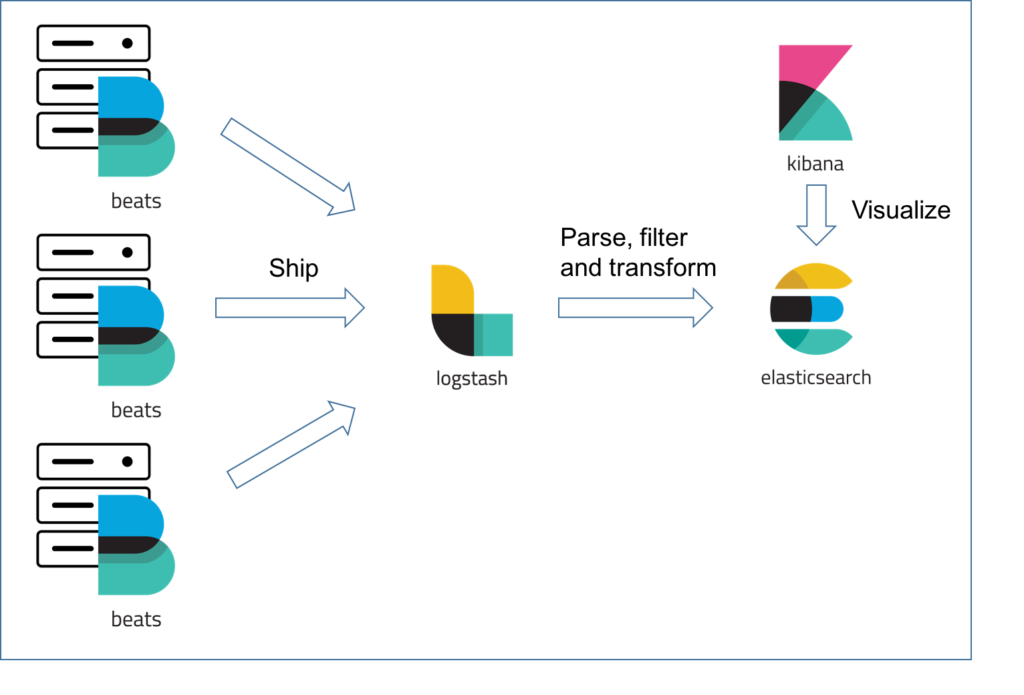
โดยทั้ง 4 ตัวแสดงการทำงานดังรูปนี้
จากนั้นทำการลงรายละเอียดของ Elasticsearch ที่สุด
จึงทำการสรุปแต่ภาพรวมในส่วนนี้
Elasticsearch มีความสามารถดังนี้
- จัดเก็บข้อมูลเป็น Document ซึ่งอยู่ในรูปแบบ JSON
- สามารถทำการค้นหาได้ดี เนื่องจากทำการสร้าง index ให้อัตโนมัติ
- สามารถใช้งานโดยไม่ต้องสร้าง schema ไว้ก่อนได้ เนื่องจากจะสร้างให้อัตโนมัติตามข้อมูล หรือเรียกว่า Dynamic schema
- สามารถทำการ analyze ข้อมูลได้ ผ่าน Aggregation API ซึ่งเป็นส่วนการทำงานที่ใช้สำหรับสร้าง visualization นั่นเอง
โดยส่วนนี้จะใช้ควบคู่ไปกับ Kibana
เนื่องจากใน Kibana ได้เตรียมเครื่องมือของการใช้งานและเรียนรู้ไว้ให้ครบ
ทั้ง Dev tools สำหรับใช้งาน Elasticsearch ผ่าน RESTFul API
เป็นสิ่งที่คนใช้งาน Elasticsearch ทั้งนักพัฒนา คนออกแบบ และ infrastructure
ต้องใช้งานได้และเป็น
ทำการเรียนรู้ทั้ง
- CRUD operation กับ Elasticsearch ผ่าน RESTFul API ที่ได้เตรียมไว้
- Query DSL ของ Elasticsearch มีเยอะมาก ๆ โดยแบ่งเป็นการ query และ filter ข้อมูล
- Analyse API สำหรับการดูขั้นตอนการจัดทำ index ของ Elasticsearch ทั้ง Tokenizer, Filter, Normalize เป็นต้น
- Aggregation API สำหรับการวิเคราะห์ข้อมูล
- Alias index และการ routing ข้อมูลตามที่ต้องการ
- Bulk API สำหรับการปรับปรุงความเร็วในการนำข้อมูลเข้า
อีกเรื่องใหม่ที่ขาดไม่ได้คือ Index Lifecycle Management (ILM)
เป็นความสามารถใหม่ เพื่อรองรับข้อมูลขนาดใหญ่
ที่สำคัญช่วยให้ Elasticsearch ทำงานได้รวดเร็วขึ้นอีกด้วย
จากนั้นช่วงท้าย ๆ ทำการอธิบายเรื่องของ Cluster
สำหรับออกแบบให้รองรับการ scale ที่ง่ายขึ้น
ยกตัวอย่างเช่น การแบ่งหน้าที่ของแต่ละ node ให้ชัดเจน
ซึ่งใน Elasticsearch นั้นโดยค่าปกติจะทำให้ที่ทุกอย่างดังนี้
- Master ทำหน้าที่ควบคุมและดูแล cluster
- Data ทำหน้าที่จัดเก็บข้อมูล
- Ingest สำหรับทำการ pre-processing และ transform ข้อมูลก่อนนำไปจัดเก็บ
- Machine learning สำหรับความสามารถใหม่คือ Machine learning นั่นเอง
- Query หรือ Coordination สำหรับทำการดึงข้อมูลและนำข้อมูลเข้าผ่าน Bulk API
ถ้าเราเข้าใจในส่วนนี้จะทำให้เรา
สามารถวางแผนในการขยายแต่ละส่วนได้ง่ายขึ้น
แต่ก็ยังมีอีกหลายเรื่องที่ยังไม่ได้แนะนำไป
- การ modeling data
- การ tuning performance
- การ monitoring
- การพัฒนาระบบงานกับ ELK stack
สุดท้ายแล้วต้องขอขอบคุณทางอาจารย์ที่ให้โอกาสไปแบ่งปันครับ