ในปัจจุบันถ้าพูดถึง Big Data แล้ว
เครื่องมือที่ตามมาในอันดับต้น ๆ น่าจะเป็น Hadoop
ดังนั้นมาลองทำความรู้จักกับมันสักหน่อย
เผื่อในอนาคตอันใกล้ อาจจะต้องสัมผัส หรือ นำมาใช้งาน
จะได้ไม่งง และ คุยกับคนอื่นรู้เรื่องบ้างสักหน่อย
Hadoop คืออะไรล่ะ
เป็น platform สำหรับมำการจัดเก็บ และ ประมวลผลข้อมูลขนาดใหญ่ (Big Data)
ซึ่งสามารถรองรับการขยายตัวของข้อมูล และ มีความน่าเชื่อถือสูง
เนื่องจากสามารถทำการประมวลผลแบบกระจาย
โดยผ่านเครื่อง computer มากมายที่อยู่ใน cluster ได้ง่าย
Hadoop ถูกสร้างขึ้นมาเพื่อให้สามารถขยายระบบ
ด้วยการเพิ่มเครื่อง computer เป็นหลักร้อยหลักพัน
มากกว่าการขยายเครื่องเดียวให้มีประสิทธิภาพที่สูงขึ้น
รวมทั้งมีระบบตรวจจับข้อผิดพลาดจากการทำงาน
และสามารถจัดการความผิดพลาดเหล่านั้นได้
ทำให้ระบบมีความน่าเชื่อถือในระดับสูง
เป็นการขายของขั้นรุนแรง ถ้าไม่เชื่อก็ลองใช้งานกันดูนะครับ
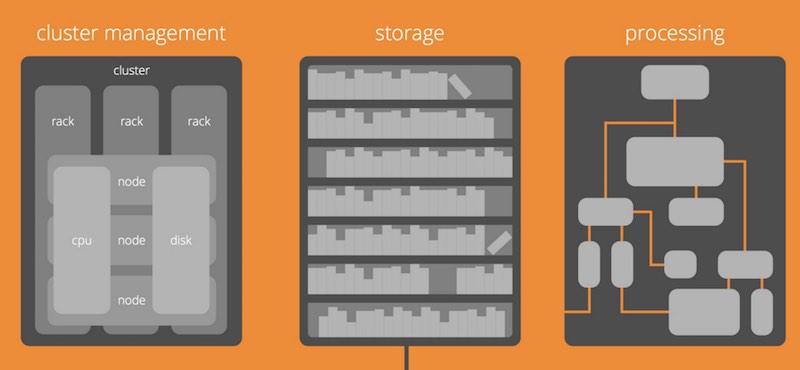
Hadoop มีส่วนการทำงานหลัก 3 ส่วน คือ
- Cluster management
- Storage
- Processing
แสดงดังรูป
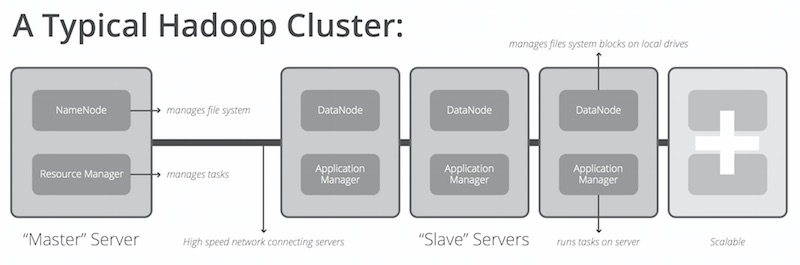
โครงสร้างพื้นฐานของ Hadoop cluster ประกอบไปด้วย
- Master server
- Slave server
แสดงดังรูป
จงจำไว้ว่า Hadoop ไม่ใช่สิ่งที่ช่วยแก้ไขปัญหาทุก ๆ อย่างนะ !!
ถ้าเทียบไปแล้ว Hadoop มันคือ ค้อนที่มีขนาดใหญ่มาก ๆ
ดังนั้นไม่เหมาะสมสำหรับนำไปตอกตะปูที่มันเล็ก ๆ
ข้อมูลก็เช่นกัน สามารถสรุปสั้น ๆ ได้ดังนี้
- อย่านำไปใช้กับข้อมูลที่มีขนาดเล็ก
- อย่านำไปประมวลผล หรือ ทำงานเพียง computer 1 เครื่อง
- โดยธรรมชาติของ Hadoop มันคือ batch processing ดังนั้นถ้าต้องการให้ทำงานแบบ real time มันไม่ง่ายเลย หรือไม่เหมาะสมเท่าไร
Hadoop นั้นมี library ที่สามารถนำมาทำงานร่วมกันได้มากมาย
เช่น
- Spark
- Hive
- Pig
- Sqoop
- Samza
- Cascading
ยังไม่พอนะ มีตำแหน่งงานสำหรับ Data Professional เยอะอีกด้วย
สามารถแบ่งออกเป็น 3 กลุ่มใหญ่ ๆ ดังนี้
- DevOps
- Development
- Data Scientist
โดยทั้งสามกลุ่มนี้จำเป็นต้องมีความรู้ความสามารถต่าง ๆ เหล่านี้
- Linux และ การใช้งานชุดคำสั่งต่าง ๆ
- มีความรู้ความเข้าใจเรื่อง Operation ต่าง ๆ ด้วย เช่น package managment, deployment เป็นต้น
- พร้อมรับต่อการเปลี่ยนแปลงที่รวดเร็ว ดังนั้นเรื่องความรู้พื้นฐานสำคัญมาก ๆ
ยังไม่พอนะ สิ่งที่คุณต้องทำอยู่เป็นประจำ คือ
ต้องเรียนรู้จากข้อมูล และ use case ต่าง ๆ ให้มากขึ้น
รวมทั้งวิธีการประมวลผลในรูปแบบต่าง ๆ
เนื่องจากในปัจจุบันมี public data จำนวนมาก เช่น
- Wikipedia
- Github
- Social network เช่น Twitter, Facebook เป็นต้น
ทั้งหมดนี้น่าจะพอทำให้เข้าใจ และ เห็นภาพโดยรวมแบบกว้าง ๆ ของ Hadoop ได้บ้างนะ
คุณพร้อมหรือยังสำหรับ Hadoop กับ Big Data
รูปทั้งหมดนำมาจาก Infogramphic ของ Think To Start :: Hadoop