
ช่วงนี้มีโอกาสใช้งาน Array ของ Numpy library
และ Series/DataFrame ของ Pandas library
สำหรับการจัดการและวิเคราะห์ข้อมูลของระบบนิดหน่อย
จากการใช้งานพบว่า
ในการเข้าถึงข้อมูลของ Pandas นั้นช้ากว่า Numpy มากพอสมควร
แต่ก็ยังเร็วกว่า Python standard library !!
จึงลองทำ profiling ดูนิดหน่อย
รวมทั้งการปรับปรุง code ให้ทำงานเร็วขึ้นบ้าง
เริ่มจากการวัดประสิทธิภาพในการเข้าถึงข้อมูล
โดยจะทำการสร้าง list ขนาด 1 ล้านขึ้นมาก่อน
- สร้าง array ด้วย Numpy
- สร้าง series ด้วย array จาก Numpy
- ทำการสุ่ม index ขึ้นมา 100 ตัว เพื่อใช้ทดสอบเข้าถึงข้อมูล
จากนั้นทำการวัดประสิทธิภาพใน iPython ได้ผลดังนี้
ผลที่ได้คือ
การเข้าถึงข้อมูลในแต่ละ index ของ Numpy เร็วกว่า Pandas อย่างมาก
นั่นคือการทำงานของ Numpy มีเวลาการทำงานอยู่ในหน่วย nanosecond
ส่วนการทำงานของ Pandas มีเวลาการทำงานอยู่ในหน่วย milisecond !!
ส่วนของ standard python อยู่ในหน่วย second !!!!
ซึ่งต่างกันมากมายหลายร้อยเท่า
ส่วนพวก operation ต่าง ๆ เช่น บวกลบคูณหารนั้นห่างกันไม่มากเท่าไร แต่ Numpy จะเร็วกว่า
คำถามที่เกิดขึ้นมาคือ แล้วใน Pandas มันไปทำอะไรนะ ถึงทำงานช้า ?
จะไปเปิด code อ่านดูก็น่าจะยากไปสำหรับการเริ่มต้น
ดังนั้นจึงลองทำ profiling และนำ SnakeViz มาช่วยในการ visualization ของการทำงาน
ด้วยคำสั่ง
In [15]: %snakeviz series[index]
พบว่า การเข้าถึงข้อมูลใน Series ของ Pandas ทำงานเยอะมาก ๆ
มีการเรียกมากกว่า 20 ชั้นสำหรับการดึงข้อมูล !!
แสดงดังรูป
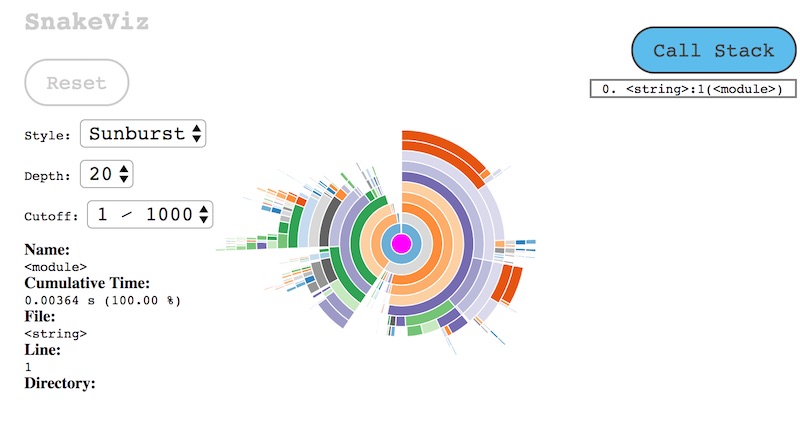
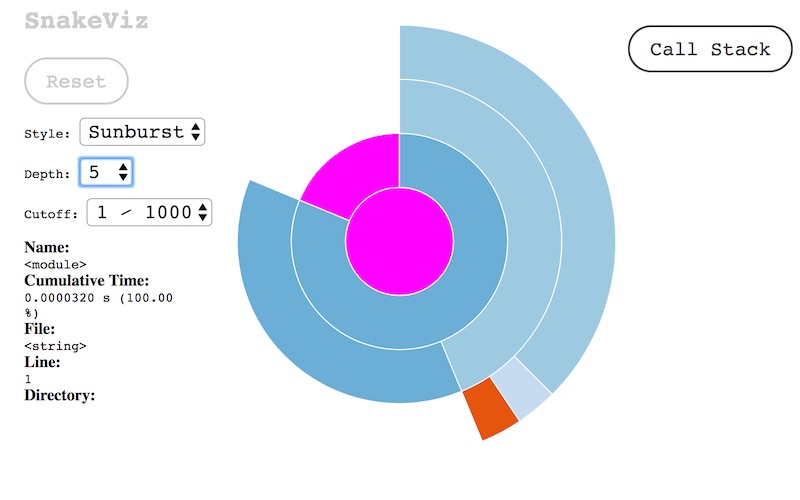
อาจจะดูแล้วยังงง ๆ ดังนั้นมาเปรียบเทียบกับการเข้าถึงข้อมูลใน array ของ Numpy
แสดงผลดังนี้ ซึ่งไม่มีการเรียกหรือทำงานอะไรที่ซับซ้อนเลย
จึงทำให้ผลการทำงานเร็วกว่ามาก ๆ
การปรับปรุง performance การทำงาน
เมื่อเราเห็นแล้วว่า Pandas มีการจัดการข้อมูลในรูปแบบ Series เยอะมาก ๆ
ดังนั้นสิ่งที่เราต้องทำคือ แก้ไขปัญหา
แทนที่จะทำการเข้าถึงข้อมูลผ่าน series
ก็ทำการเปลี่ยนข้อมูลจาก series มาอยู่ในรูปแบบของ array ด้วย Numpy ก่อน
ยกตัวอย่างเช่น
โดยการทำงานของการเรียกใช้ property values นั้น
มี performance ที่ดีมาก ๆ และได้ข้อมูลชนิด array numpy (numpy.ndarray)
เมื่อได้ข้อมูลที่ต้องการก็นำไปใช้งานต่อไป
ขอให้สนุกกับการ coding ครับ





