มาทำความรู้จักกับ 4 ข้อสุดท้ายสำหรับ The Twelve-Factor App
โดยในส่วนนี้จะเป็นส่วนของผู้ดูแลระบบ ประกอบไปด้วย
- Disposability
- Dev/prod parity
- Logs
- Admin processes
มาดูในรายละเอียดกัน
ข้อที่ 9 Disposability
Maximize robustness with fast startup and graceful shutdown
การทำงานของ process นั้น
ควรเริ่มทำงานได้อย่างรวดเร็ว
รวมทั้งเมื่อต้องการปิดหรือ shutdown จะต้องเป็น graceful shutdown ด้วย
คำถามคือ graceful shutdown มันคืออะไร ?
อธิบายง่าย ๆ คือ ใช้อะไรอยู่ ก็ต้องคืนอย่างถูกต้อง ก่อนที่จะทำการปิดหรือ shutdown นั่นเอง
ยกตัวอย่างเช่น resource ต่าง ๆ เช่น Database connection และ Queue เป็นต้น
รวมไปถึงถ้ายังมีการทำงานค้างอยู่เช่น Data processing
ก็ต้องรอหรือทำให้เสร็จแบบถูกต้อง ไม่ส่งผลเสียต่อระบบ
เช่น ข้อมูลหายหรือการประมวลผลที่ไม่ถูกต้อง
หรือ Database connection ไม่ถูกคืนให้กับระบบ
ความซวยบังเกิดแน่นอน
ดังนั้นระบบงานหรือ service หรือ process ของเรา
ต้องมีคุณสมบัติทั้งสองอย่างเสมอ คือ เริ่มต้นได้เร็วและจบได้สวย
ตัวอย่างของการทำงานของ Graceful shutdown ของ Web server
- Web application ได้รับคำสั่งให้หยุดหรือ kill process (ได้รับผ่าน SIGTERM)
- ถ้าระบบ Web application รับงานผ่าน Load Balance แล้ว ก็จะทำการแจ้งไปยัง Load Balance ว่าไม่ต้องส่ง request มาให้นะ
- ส่วน Web application เครื่องอื่น ๆ ก็ทำงานปกติไป
- ระบบ Web application ทำการคืน resource ต่าง ๆ รวมทั้งทำงานที่ค้างไว้ให้เสร็จ ทั้ง Database connection และ Queue เป็นต้น
- เมื่อทุกอย่างในข้อ 4 เรียบร้อยแล้ว Web application จึงจะหยุดทำงานและส่งค่าสถานะ success ออกไป
มาดูระบบตัวอย่างที่พัฒนาด้วยภาษา Python กันบ้าง
เราจะทำ Graceful shutdown อย่างไร ?
ไม่ต้องคิดมากนะ แค่ค้นหาก็เจอ เจอหลายแบบด้วย
มาดูตัวอย่างกัน
เป็นตัวอย่างการทำงานดักจับในกรณีที่ต้องการปิด process
ถ้าอยู่ในแนวทางของ Containerization เช่น Docker swarm และ Kubernetes แล้ว
หมายความว่า เมื่อ container และ Pod ตายไป จะต้องไม่ส่งผลกระทบต่อการทำงานนั่นเอง
โดยที่ Containerization นั้นถูกสร้างขึ้นมาตามแนวทางนี้อยู่แล้ว
แต่ source code ของเราละ เขียนมาเพื่อสนับสนุนหรือไม่ ? ถามใจดูเอานะ
ข้อที่ 10 Dev/prod parity
Keep development, staging, and production as similar as possible
แนวคิดนี้มีเป้าหมายเพื่อลดความต่างของ environment ต่าง ๆ กับ production environment ให้เหลือน้อยที่สุด
ทั้งในแง่ของเวลา
นั่นคือนักพัฒนาใช้เวลาในการพัฒนาบน development server นานหรือไม่ กว่าจะ deploy ไปยัง production server
ทั้งในแง่ของ process การทำงาน
นั่นคือทีมพัฒนาก็เขียน code กันไป ส่วนการ deploy เดี๋ยวให้อีกทีมทำให้ รอกันไปมา โยนกันไปมา
ทั้งในแง่ของเครื่องมือ
นั่นคือทีมพัฒนาอาจจะใช้ server เล็ก ๆ ทุกอย่างกองรวมกัน database ไม่เหมือนจริง web server ก็ configuration ไม่เหมือน production เช่น พัฒนาบน Windows OS แต่การ deploy ทำบน Linux !!
ดังนั้นจะทำอย่างไร เพื่อให้สามารถนำการเปลี่ยนแปลงต่าง ๆ
จากการพัฒนาให้ไป deploy ยัง production environment ให้เร็วและมีคุณภาพที่ดี
บางครั้งเราจะเรียกกระบวนการนี้ว่า Continuous Integration และ Continuous Deployment
เพื่อทำให้เรามั่นใจว่า สิ่งต่าง ๆ ที่พัฒนาขึ้นมายังคงทำงานได้ถูกต้องตามที่คาดหวัง
และเกิดปัญหาให้น้อยที่สุด หรือ ให้รู้ปัญหาได้อย่างรวดเร็ว
แน่นอนว่าในโลกของ Containerization เกิดมาเพื่อสิ่งนี้เลย
ทั้ง Docker ที่สามารถใช้งานได้ในระบบปฏิบัติการหลัก ๆ ได้
แถมยัง compatible กันอีก ดังนั้นจึงหมดหรือลดปัญหาเรื่อง environment ไปได้เลย
ตัวอย่างเช่น
การใช้งาน docker compose สามารถที่จะสร้างไฟล์ docker-compose.yml
จากนั้นก็สั่งด้วย $docker-compose up ได้เลย
จะได้ระบบงานที่มีรูปแบบเหมือนกันในทุก ๆ environment ที่มี Docker engine อยู่
ยิ่งพวก Kubernetes นั้น
สามารถแยก environment ต่าง ๆ ด้วย namespaces ได้ง่าย ๆ อีกด้วย
ข้อที่ 11 Logs
Treat logs as event streams
ปกติเราดู log กันอย่างไร ?
ยังเก็บลง log file และคอยดูแบบนี้ไหมนะ ?
$tail -f access_log ไหมนะ ?
ถ้ายังทำอยู่ เปลี่ยนเถอะนะ
เนื่องจากข้อมูล log ต่าง ๆ มันคือ event ที่เกิดขึ้นตามช่วงเวลาต่าง ๆ
ดังนั้นแนะนำให้ทำการพ่น log ออกมายัง stdout หรือ Standard Output
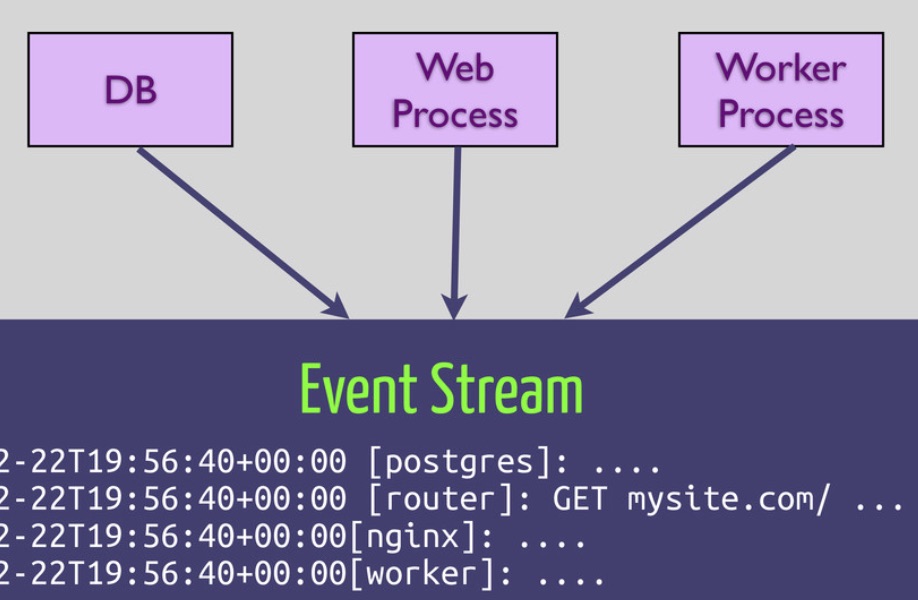
จากนั้นให้ทำการจัดเก็บข้อมูล log เหล่านี้ และส่งไปยังระบบจัดการต่อไป
ยกตัวอย่างการใช้งานเช่น
- ELK (Elasticsearch Logstash Kibana)
- EFK (Elasticsearch Fluentd Kibana)
- Fluentd with Docker
แต่ระบบ Logs ที่ดี ควรดูได้ง่าย เข้าใจง่าย
แจ้งการทำงานที่ผิดปกติ ก่อนที่มันจะทำร้ายระบบ
รวมทั้งทีมต้องเข้าใจด้วยว่า มันคืออะไร มีประโยชน์อะไร ดูอย่างไร
มิเช่นนั้นมันจะสวยอย่างเดียว แต่จูบไม่หอมนะ
ข้อที่ 12 Admin processes
Run admin/management tasks as one-off processes
แนวคิดนี้ต้องการให้แยกงานส่วนการดูแลรักษาระบบออกจาก app ซะ
ยกตัวอย่างเช่น
การ migrate database
การ scale service/process ของระบบ
แต่ยังคงทำงานใน environment, source code และ configuration เดียวกัน
โดยถ้าใช้ docker แล้ว
เราสามารถทำการเข้าถึง container ด้วยคำสั่ง
$docker container exec -i --entry-point container_name path_of_entry_point
ซึ่ง entry point ของไฟล์ที่ใช้สำหรับจัดการงานต่าง ๆ
จบซะทีสำหรับ The Twelve-Factor App ทั้ง 12 ข้อ
จะเห็นได้ว่า แนวคิดทั้ง 12 ข้อนั้น ไม่ได้ใช้ได้กับ Cloud application เท่านั้น
ยังสามารถนำมาประยุกต์ใช้กับการพัฒนาระบบทั่วไปได้
ทั้ง web application, desktop application ได้อีกด้วย
การนำไปใช้งาน ไม่จำเป็นต้องใช้ครบทั้ง 12 ข้อ
เพียงนำบางข้อมาใช้เพื่อแก้ไขปัญหา หรือ ปรับปรุงระบบให้ดียิ่งขึ้นก็ได้
แต่เหนือสิ่งอื่นใด เมื่อเรานำแนวคิดมาใช้งานต้องจำไว้ว่า
- Declarative setup ช่วยทำให้เวลาในการ setup ระบบเร็วขึ้น
- Clean contracts ทำให้ส่วนงานต่าง ๆ ไม่ผูกมัดกันแน่น นั่นคือเปลี่ยนแปลงได้ง่าย
- Deploy practices ช่วยทำให้การ deploy และ scale out สะดวกขึ้น
- Minimize divergence สนับสนุนเรื่องของ Continuous Deployment
สุดท้ายมันคือ การปรับปรุงอย่างต่อเนื่อง
แต่ว่าปัญหาของคุณคืออะไร
เรื่องต่าง ๆ เหล่านี้มันช่วยคุณได้หรือไม่
ลองพิจารณาดูก่อนนะ
อ่านแนวคิดนี้ข้ออื่น ๆ ได้จาก blog ด้านล่างนี้
Part 1 :: การพัฒนาระบบตามแนวคิด 12 Factor
- Codebases
- Dependencies
- Configs
- Backing services
Part 2 :: การพัฒนาระบบตามแนวคิด 12 Factor
- Build, release, run
- Processes
- Port binding
- Concurrency
ขอให้สนุกกับการ coding ครับ