
จาก Part ที่ 1 สรุปปัญหาและการนำแนวคิดของ Microservices มาใช้งานและแก้ไขปัญหา
มาใน Part ที่ 2 มาดูแนวทางการใช้งานกัน
ซึ่งทางทีมพัฒนาของ Medium.com ได้แบ่งแนวทางการนำ Microservices มาใช้ ออกเป็น 7 ข้อ
มาดูกันว่าแต่ละข้อเป็นอย่างไรบ้าง ?
ข้อที่ 1 Build new services with clear value
เนื่องจากการสร้าง service ใหม่ มันมีค่าใช้จ่ายเสมอ
รวมทั้งอาจจะต้องหยุดพัฒนาของเก่าอีกด้วย
ถ้าหยุดพัฒนาของเก่าเป็นเวลานาน ๆ
ไม่น่าจะส่งผลดีต่อ business แน่ ๆ
ดังนั้น การเขียนใหม่ ออกแบบใหม่ทั้งระบบไม่น่าจะเป็นทางเลือกที่ถูก
Service ที่สร้างขึ้นมาใหม่นั้น มันมีคุณค่าชัดเจนหรือไม่ เอาให้ชัด
ว่ามีคุณค่าต่อ business/product หรือ engineer
แต่ถ้าการลงแรงทำไป มันไม่ได้ให้คุณค่าอะไรเลย ก็อย่าไปทำเลย ให้มันอยู่ของมันไป
ดังนั้นแนะนำให้เริ่มที่ monolith ก่อน
จากนั้นมันจะช่วยให้เราง่ายต่อการนำ Micorservices มาใช้งาน
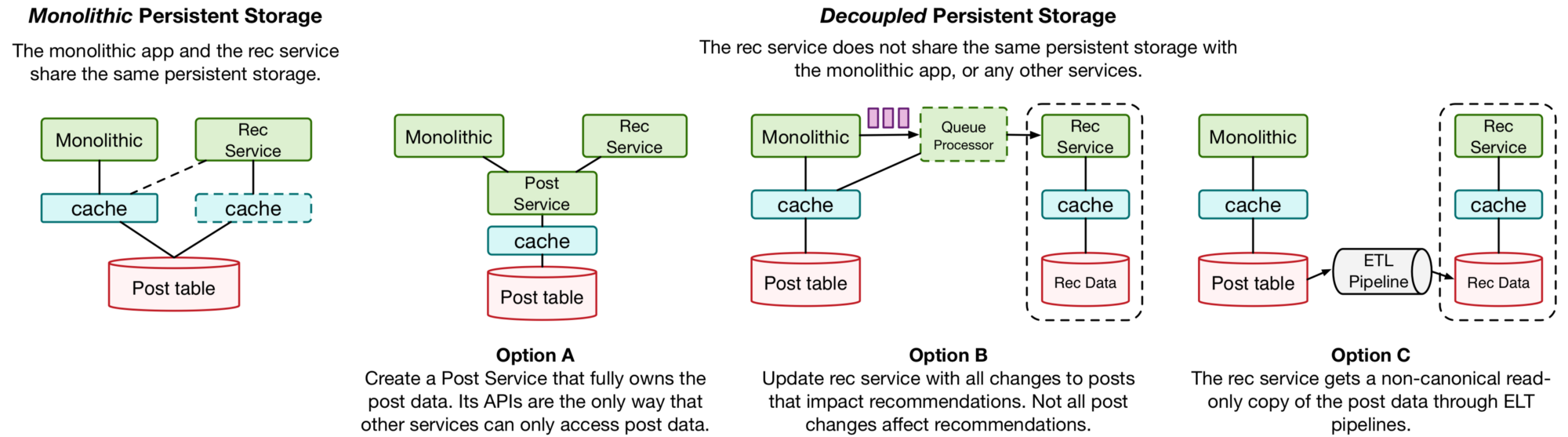
ข้อที่ 2 Monolithic persistent storage considered harmful
ปัญหาของการนำ Microservices ไปใช้งานคือ
นักจะแยกออกเป็น service ย่อย ๆ ตาม model/domain ก็ว่าไป
แต่สิ่งที่พบเจอมากสุด ๆ คือ Monolithic persistent
Monolithic persistent คือ ทุก ๆ service ใช้งานที่จัดเก็บข้อมูลเดียวกัน
เนื่องจากมันง่ายต่อการพัฒนาและให้แต่ละ service ทำงานร่วมกัน
แต่ผลที่ตามมาคือ
- แต่ละ service ผูกมัดกันอย่างแรง (Tight coupling)
- เมื่อมีการแก้ไขที่จัดเก็บข้อมูล จะส่งผลกระทบในทุก ๆ service
แสดงตัวอย่างของ Monolithic persistent
ดังนั้นควรต้องแยก persistent ออกมาในแต่ละ service ดังรูป
ข้อที่ 3 Decouple “building a service” and “running services”
การสร้าง service ที่ว่ายากแล้ว
การ deploy/run service จะยากยิ่งกว่า
เพราะว่าถ้าแต่ละ service ที่เราทำการ deploy/run ขึ้นไปนั้น
มันต้องไปยุ่งเกี่ยวกับ service อื่น ๆ มากเท่าไร
ก็จะทำให้ทีมช้าลงไปมากเท่านั้น
ดังนั้นสิ่งที่ควรทำคือ
ถ้าแยกแต่ละ service ออกกันอย่างชัดเจนแล้ว
ควรต้องแยกตอนที่มันทำงานด้วย
นั่นคือแต่ละ service ต้องแยกออกกันอย่างชัดเจนทั้งตอนสร้างและทำงาน
สิ่งที่ต้องเตรียมการประกอบไปด้วย
เรื่องของ network
เรื่องของ communication protocol
เรื่องของการ deploy
เรื่องของการ monitoring
ที่ Medium.com นั้นจัดการเรื่องต่าง ๆ ตามนี้
- จัดการ network ด้วย Istio และ Envoy
- ใช้ gRPC สำหรับให้แต่ละ service ติดต่อสื่อสารกัน
- การ deploy จะใช้ AWS ECS และ Kubernetes
ข้อที่ 4 Thorough and consistent observability
สิ่งที่สำคัญมาก ๆ ในการพัฒนาระบบงานหรือ service คือ
เรารู้ไหมว่าระบบงานหรือ service ของเรานั้นทำงานอย่างไร ?
เรารู้หรือไม่เมื่อเกิดปัญหา ?
เรารู้จุดที่เกิดปัญหาหรือไม่ ?
ดังนั้นเรื่องของ logging, tracing, metric, alert และ dashboard ขาดไม่ได้เลยนะ
ยิ่งในโลกของ Microservice ที่มีจำนวน service เยอะยิ่งจำเป็นต้องมีเสมอ
และควรมีระบบต่าง ๆ เหล่านี้ตั้งแต่เริ่มต้น
และควรใช้เครื่องมือที่เหมือน ๆ กันในทุก ๆ service และทีม
ยกตัวอย่างที่ Medium.com จะใช้งาน
ข้อที่ 5 Not every new service needs to be built from scratch
ในการสร้าง service ใหม่ ๆ ขึ้นมานั้น
ไม่จำเป็นต้องสร้างใหม่จากศูนย์ เพราะว่ามันต้องใช้ค่าใช้จ่ายสูงมาก ๆ
สิ่งที่ควรทำกว่าคือ
การแยก service ใหม่ออกมาจากระบบ monolith จะดีกว่า
ดังนั้นระบบงานเรา ต้องทำการออกแบบให้ดีด้วย
แล้วจะทำให้ง่ายต่อการแยกมาเป็น service ใหม่
หรือใช้ technology ที่คุ้นชินมาช่วยพัฒนา service ใหม่
แต่ถ้า technology เดิมมันไม่สนับสนุนหรือไม่เหมาะกับงาน
ก็ควรใช้สิ่งใหม่ ๆ ที่เหมาะสม
แต่สิ่งใหม่ ๆ ที่นำมาใช้งาน ก็ต้องดูเรื่องค่าใช้จ่ายต่าง ๆ
เช่น การศึกษา การดูแล ว่าเป็นอย่างไรบ้าง ?
ข้อที่ 6 Respect failures because they will happen
ทุกสิ่งทุกอย่างมันทำงานผิดพลาดได้เสมอ
ยิ่งในระบบการทำงานแบบกระจายยิ่งมีโอกาสเกิดขึ้นบ่อยมาก ๆ
ดังนั้นการจัดการระบบงาน เมื่อเกิดข้อผิดพลาดต่าง ๆ ขั้นมา จึงเป็นสิ่งจำเป็นมาก ๆ
คิดให้มาก ทดสอบให้มาก และจัดการกับปัญหาได้ดี
ทุก ๆ ส่วนสามารถเกิดปัญหาได้เสมอ
ดังนั้นอย่างแรกต้องทำใจก่อน
จากนั้นต้องมีระบบ logging/tracing/alert เพื่อแจ้งหรือแสดงผลเมื่อเกิดปัญหาขึ้นมา
ทำการทดสอบระบบหรือ service ใหม่ ๆ อยู่อย่างเสมอ
ในปัจจุบันจะมีการทดสอบแบบ fail ๆ
เช่นลองสุ่มปิดเครื่องหรือ service
เช่นลองสุ่มตัด network
สิ่งที่ควรจะเกิดขึ้นมา หลังจากที่เกิดข้อผิดพลาดขึ้นมา คือ
ระบบต้องสามารถ auto-recovery กลับมาให้ได้
ข้อที่ 7 Avoid “microservice syndromes” from day one
Microservice นั้นไม่ใช่จะมาช่วยแก้ไขปัญหาทุกอย่าง
แต่มันแก้ไขได้บางอย่างเท่านั้น
บ่อยครั้งอาจจะมีความคิดว่า
ถ้าเราไม่คิดตาม Microservice ตั้งแต่แรกแล้ว
มันจะทำให้ระบบยุ่งเหยิงมาก ๆ และ cost หรือค่าใช้จ่ายที่ตามมาสูงมาก ๆ
ดังนั้นมันจะทำให้เราคิดเยอะมาก ๆ ออกแบบเยอะมาก ๆ
ถ้าเป็นลักษณะนี้ แสดงว่าเรากำลังอยู่ในอาการ Microservice Syndromes
ถ้าไม่ชัด มาดูตัวอย่างของอาการนี้กัน
- เราจะแยก service ให้เยอะ ๆ เข้าไว้
- อนุญาตให้แต่ละ service สามารถใช้ technology ที่หลากหลายได้ ซึ่งมันกลับส่งผลต่อการจัดการและดูแลรักษาอย่างมาก ทำให้แต่ละทีมแยกกันตาม technology อีกด้วย
- การสร้างและการ run services ขึ้นมา จะเพิ่มความซับซ้อนรวมทั้งทำให้เราช้าลง
- ที่จัดเก็บข้อมูลยังรวมกัน อันนี้ไม่น่ามีใครทำ
- Service เยอะมาก ๆ แต่ขาดเรื่องของ tracing, logging ทำให้ยากต่อการหาจุดผิดพลาด
สิ่งที่น่าสนใจมาก ๆ จากกรณีของ Medium.com คือ
It is fine to start with a monolithic architecture,
but make sure to modularize it
and architect it with the above three microservice principles (single purpose, loose coupling and high cohesion),
except that the “services” are implemented in the same tech stack,
deployed together and run in the same process.
นั่นคือการทำ monolithic ให้ดีนั้นสำคัญและจำเป็นอย่างมาก
ดังนั้นก่อนอื่นกลับมาดูระบบของเราก่อนว่าเป็นอย่างไร
Referecen Websites
https://medium.engineering/microservice-architecture-at-medium-9c33805eb74f
สรุปบทความเรื่อง Microservices Architecture ของ Medium.com Part 1





