
วันนี้มาเรียนพื้นฐานของภาษา R ชื่อ course ว่า R programming for (young) Data Scientist
เป็นหนึ่งใน course ที่อยู่ในงาน Predictive Analytic and Data Science conference
ถือได้ว่า เป็นการเรียนรู้ภาษาใหม่ ๆ อีกครั้งหนึ่ง
โดยเนื้อหาต่าง ๆ ใน course นี้จะเป็นฉบับพื้นฐาน
แต่ก็ทำให้รู้ และ เข้าใจว่าต้องศึกษาเพิ่มเติมและนำไปใช้อย่างไรบ้าง
เครื่องมือที่ใช้งานประกอบไปด้วย
- R language สามารถ download ได้จาก CRAN repository
- R Studio เป็น IDE สำหรับเขียนโปรแกรมด้วยภาษา R
หรือถ้าไม่อยากใช้งาน IDE ก็สามารถใช้งานผ่าน R Interactive ก็ได้
คือเข้าไปที่ command line แล้วพิมพ์ R
จะเข้าสู่ mode ของ R interactive
แต่ใช้ R Studio ชีวิตจะง่ายกว่านะ
มาเริ่มเขียน code กันเลย
พื้นฐานมันสำคัญมาก ๆ
เริ่มจากการประกาศตัวแปร การ assign ค่าลงในตัวแปร
ซึ่งสามารถทำได้ 2 แบบคือ
a = 2 2 -> a
ถ้าต้องการให้แสดงผลลัพธ์จากการทำงานตลอด
โดยไม่ต้อง print ค่าออกมาดูเอง
ให้ทำการเขียนดังนี้
(a = 2) (2 -> a)
จากนั้นทำการกำหนด Working directory
ซึ่งทำได้หลายแบบ
แต่ถ้าไม่อยากผูกติดกับเครื่องมือ ก็ใช้คำสั่ง
getwd()
setwd('<your working directory>')
ผู้สอนแนะนำให้ศึกษาแต่ละคำสั่งหรือ function จาก help()
ซึ่งมันมีความสำคัญอย่างมาก และ มันอยู่ใกล้เรามาก ๆ
เช่น ถ้าต้องการอยากรู้ว่า setwd คืออะไร และ ใช้งานอย่างไร ?
สามารถพิมพ์ว่า help(setwd) เพื่อดูรายละเอียดได้เลย
เป็นสิ่งที่นักพัฒนาต้องไม่พลาด !!
ต่อมาแนะนำให้ลองดู demo project หรือ code ที่มากับ R
ซึ่งมีประโยชน์อย่างมากต่อผู้เริ่มต้นศึกษา
เพราะว่า ตัวอย่างมีทั้ง code และแสดงผลการทำงานให้เห็นเลย
สามารถดู demo ด้วยคำสั่ง
demo() #ดูว่ามี demo เรื่องอะไรบ้าง demo(graphics) #ดู demo ของ package graphics
ผลการทำงานจาก demo
จากนั้นเข้าเรื่องของ Data type หรือชนิดของข้อมูล
ประกอบไปด้วย
- Scala
- Vector
- Matrix
- Data frame
- List
โดยในแต่ละ Data type สามารถใช้งาน function พื้นฐานต่าง ๆ ได้อีก
ประกอบไปด้วย
- Mean
- Max
- Min
- Average
- Sum
- Exp
- Log
- Sqrt
และอื่น ๆ อีกมากมายรวมทั้ง operator ต่าง ๆ เช่น +, -, *, / และ ^ เป็นต้น
ยกตัวอย่างการใช้งาน Vector
เริ่มจากการสร้าง Vector
vector1 = c(1, 2, 3 ,4 ,5) vector2 = c(1:5) vector3 = seq(from=1, to=5, by=1) random_vector = rnorm(5) empty_vector = c()
สิ่งที่น่าสนใจคือ c มันคืออะไร ?
แนะนำให้ใช้ help(c)
จะพบว่า c มันคือ Combine values into Vector or List
พร้อมยกตัวอย่างการใช้งาน
เห็นไหมว่า help มันช่วยเหลือเราได้มากเลยนะ
ยกตัวอย่างการใช้งาน Matrix
เป็นชนิดข้อข้อมูลอีกแบบที่ถูกใช้งานเยอะ
เราสามารถสร้างได้ดังนี้
vector1 = c(1, 2, 3 ,4 ,5, 6) matrix1 = matrix( vector1, nrow=3 ) #กำหนดให้มี 3 row matrix2 = matrix( vector1, ncol=2 ) #กำหนดให้มี 2 column
สามารถนำ matrix มาบวก ลบ คูณหารกันได้
รวมไปถึงการหา invert matrix และ Diagonal matrix ได้แบบสบาย ๆ
ถึงตรงนี้ต้องไปเปิดตำราเรียนกันใหม่เลยทีเดียว !!
แต่สิ่งที่มีประโยชน์ และ ใช้งานมาก ๆ คือ Data frame
มันคือข้อมูลที่เราสามารถกำหนดชื่อ column ของข้อมูลได้
และเราสามารถดึงข้อมูลมาใช้งานง่าย ๆ มาก
ทำการสร้าง Data frame โดยสร้างจาก vector นั่นเอง ดังนี้
ทำการสร้างข้อมูล 3 column ขึ้นมา คือ a, b, c
x = c(1,2,3) y = c(10,20, 30) z = c(100,200,300) t = data.frame(a=x, b=y, c=z)
จากนั้นถ้าต้องการดึงข้อมูลในแต่ละ column มาใช้งาน
สามารถทำได้ดังนี้
t$a
t[['a']]
t[, 'a' ]
t[, c('b', 'a')] #ดึงหลาย ๆ column
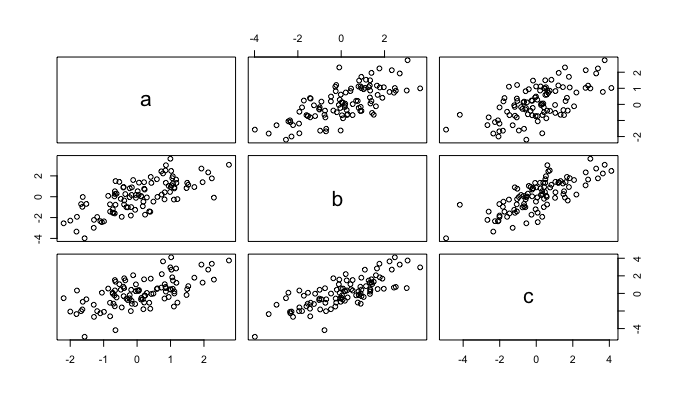
มาทำ workshop เรื่อง Data frame กันนิดหน่อย
โดยให้ทำการ random ข้อมูลขึ้นมา 3 ชุด
จากนั้นทำการสร้าง Data frame และ แสดงผลในรูปแบบ graph ด้วย plot
สามารถเขียน code ได้ดังนี้
x1 = rnorm(100) x2 = rnorm(100) x3 = rnorm(100) t3 = data.frame(a=x1, b=x1+x2, c=x1+x2+x3) t3 plot(t3)
แสดงผลการทำงานดังนี้
จากนั้นก็ทำการเรียนเกี่ยวกับเรื่องการวาด graph เพิ่มเติม
เช่น
- plot
- line
- points
ซึ่งทางผู้สอนแนะนำให้ใช้งาน ggplot2 package เนื่องจากมันแจ่มมาก ๆ
สามารถ Download เอกสารการใช้งานได้จาก ggplot2 cheatsheet
มาถึง Package ที่แจ่มมาก ๆ คือ dplyr
ใช้สำหรับการจัดการข้อมูล ก่อนนำไปวิเคราะห์ต่อไปนั่นเอง
ซึ่งเราต้องติดตั้งเพิ่มเติม ด้วยคำสั่ง
install.packages("dplyr")
ส่วนการใช้งานขั้นพื้นฐานก็มีหลายอย่างเช่น
- การแสดงข้อมูลในรูปแบบต่าง ๆ เช่นแบบตารางใน console หรือ ใน R Studio
- การกรองข้อมูล ซึ่งในส่วนนี้สนุกมาก ๆ นำเอาหลักการของ data pipeline มาใช้
- การลบข้อมูลที่ซ้ำซ้อนออกไป
- การดึงเฉพาะข้อมูลที่ต้องการมาใช้งาน หรือ การ slice data
- ถ้าต้องการดูเพิ่มเติมไปที่ help ได้เลย
โดยรวมแล้วข้อมูลมันอยู่ในรูปแบบของ Data frame นั่นเอง
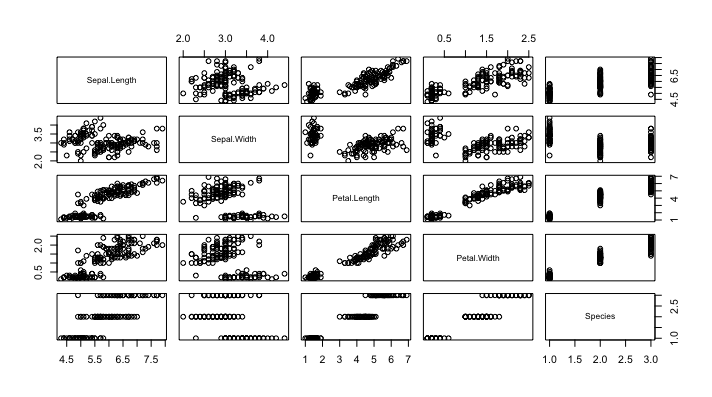
มาดูตัวอย่างจากการทำ workshop แบบ step-by-step
โดยใช้ข้อมูลตัวอย่างชื่อว่า iris flower dataset
ถ้าลอง plot ออกมาเป็นดังนี้
หรือแสดงข้อมูลในรูปแบบอื่น ๆ ได้เช่น
install.packages("dplyr")
(table_iris = tbl_df(iris)) #Table in console
View(iris) #Table in R Studio
glimpse(iris)
จากนั้นมาดูเรื่องของการ Filter ข้อมูลแบบใช้ Data pipeline เข้ามาช่วยเหลือ
สิ่งที่ต้องการคือ
- ทำการกรองข้อมูล iris ที่มีค่าของ column Sepal.Length > 7 ขึ้นไป
- เลือกเอาเฉพาะ column Sepal.Length, Sepal.Width และ Species เท่านั้น
สามารถเขียน code ได้ดังนี้
iris %>% filter(Sepal.Length>7) %>% select(Sepal.Length, Sepal.Width, Species)
คำถามต่อมาคือ ถ้าต้องเก็บผลการทำงานไว้ในตัวแปรล่ะต้องทำอย่างไรดี ?
ซึ่งสามารถทำได้ 2 แบบ คือ
result = iris %>% filter(Sepal.Length>7) %>% select(Sepal.Length, Sepal.Width, Species) iris %>% filter(Sepal.Length>7) %>% select(Sepal.Length, Sepal.Width, Species) -> result
สำหรับผมชอบแบบที่ 2 เพราะว่ามันดูสวยงามและต่อเนื่องดี
ที่สำคัญมันอ่านจากซ้ายไปขวาอีกด้วย
และยังมี Package อื่น ๆ ที่ทางผู้สอนแนะนำให้ศึกษาเพิ่มเติม
เช่น
- dplyr สำหรับจัดการข้อมูล ซึ่งมันมีวิธีการอีกเยอะมาก ๆ
- Forecast สำหรับการทำนายผลจากข้อมูล
- ggplot2 สำหรับการแสดงผลในรูปแบบ graphic
ผมเขียนบันทึกและ source code ต่าง ๆ ไว้ที่ Github :: Learn R programming
โดยรวมแล้วเป็นภาษาที่สนุกมาก ๆ
แถมมี package ต่าง ๆ เยอะมาก ๆๆๆๆๆ
ดังนั้นนักพัฒนาไม่ควรหยุดศึกษา
ยิ่งเรื่องของสถิติ คณิตศาสตร์ ไปจนถึงพวก Data Mining, Machine Learning แล้ว
เป็นสิ่งที่ขาด หรือ พลาดไม่ได้เลยนะ
ขอตัวไปศึกษาต่อก่อน !!





