ในตอนนี้ทาง Netflix กำลังทำการพัฒนาส่วนของ web application ใหม่ด้วย Node.js
สิ่งหนึ่งที่ทีมพัฒนาได้นำประสบการณ์การเรียนรู้เรื่อง Tunning performance
และได้สรุปไว้ใน blog เรื่อง Node.js in flames
มาดูกันว่าทีมพัฒนาใช้วิธีการอะไรในการหา root cause ของปัญหา
เพื่อใช้ในการตัดสินใจเลือกงาน API framework
ในบทความนี้คือ ปัญหาของ Express.js
อาการของปัญหาที่พบ
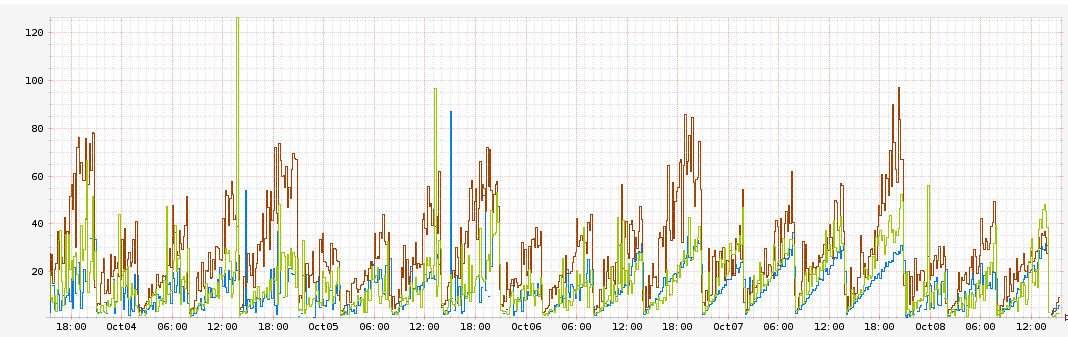
ทีมพัฒนาพบว่า ค่า latency การทำงานของระบบจะเพิ่มขึ้น 10ms ใน 1 ชั่วโมง
และในช่วงที่มีค่า latency สูงๆ ระบบก็จะใช้งาน CPU มากขึ้นตามไปด้วย
เมื่อค่า latency สูงไปถึง 60ms แล้ว server จะทำการ reboot กราฟแสดงดังรูป
การแก้ไขปัญหาเบื้องต้น
สิ่งที่ทีมพัฒนาได้ตั้งสมมุติฐานไว้ว่า น่าจะมีอะไรที่ทำงานผิดพลาดไป เช่น memory leak หรือไม่
ดังนั้นจึงได้ทำการสร้าง environment สำหรับการทำ load test ขึ้นมา
โดยทำการกำหนดขนาดของ Node.js heap ไว้ที่ 32 GB
ผลจากการทดสอบ ก็ยังพบว่าค่า latency ยังสูงขึ้นในลักษณะเดิม
รวมทั้ง CPU ก็ถูกใช้งานสูงเช่นเดิม
ดังนั้นทีมพัฒนาจึงต้องทำการหาปัญหาในระดับที่ลึกกว่านี้แล้ว …
วิธีการหา root cause และแก้ไขปัญหา
เริ่มต้นการทำ profile ในการใช้งาน CPU ของระบบงาน
โดยจะใช้ CPU Flame graph และ Linux Perf Events มาช่วย
ผลการทำ profile ออกมา
พบว่า ทีมพัฒนา code ที่มีการอ้างอิงถึง
การทำงานของ router handler ของ Express.js จำนวนมาก แสดงดังรูป

ต่อมาจึงทำการเข้าไปดูการทำงานอย่างละเอียดของ Express.js ก็พบว่า
- ทุกๆ endpoint มันถูกจัดเก็บไว้เพียงที่เดียว (Global arrray)
- Express.js ทำการ recursive ตัวมันเองเพื่อเลือก route handler ที่ถูกต้อง
จาก Data Structure คือ Array นั้น ทีมพัฒนาคิดว่า
มันไม่น่าจะเป็นสิ่งที่เหมาะสมกับการทำงาน
เพราะว่าในการค้นหา route handler นั้นมีค่าสูงสุดคือ O(n)
ซึ่งนั่นคือที่มาของการทำงานเยอะมากๆ ที่เห็นใน Flame graph
ดังนั้น จากสมมุติฐานข้อนี้
ทางทีมพัฒนาจึงได้ลองสร้าง code ตัวอย่างง่ายๆ ขึ้นมา
เพื่อดูพฤติกรรมการทำงานของ route handler ของ Express.js
ก็พบว่าส่วนนี้คือ ปัญหาหลักจริงๆ
เมื่อทำการ monitoring ขนาดของ Global array ในขณะที่ทำการ load testing
ก็พบว่าขนาดของ Global array ใหญ่ขึ้นเรื่อยๆ ตามค่า latency ที่เพิ่มขึ้น
จากนั้นทีมพัฒนาจึงเริ่มการแก้ไข code ของ Express.js ใหม่
ด้วยการแก้ไขการทำของ route handler โดยทำการลบ route handler เก่าออกไป และ เพิ่ม route handler ใหม่เข้าไป
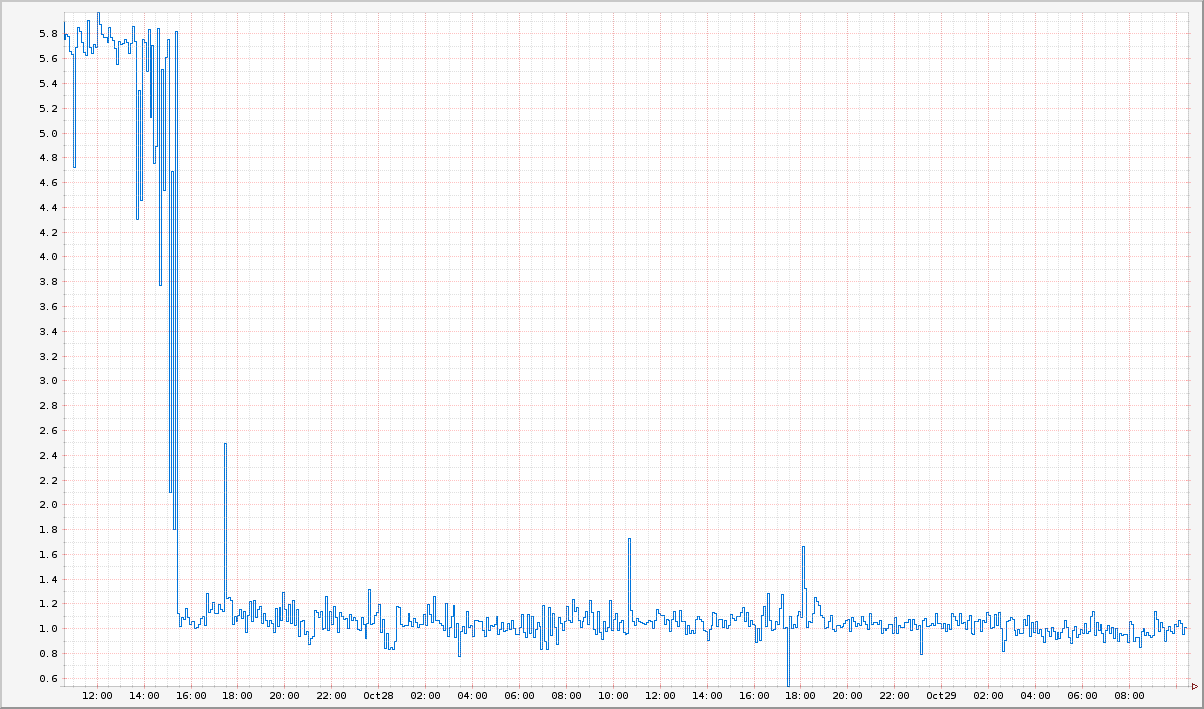
ผลที่ได้รับจากการแก้ไขคือ ค่า latency ลดลงมาเหลือ 1 ms ดังรูป
ข้อสรุป และ สิ่งที่ได้เรียนรู้
ทีมพัฒนาได้สรุปสิ่งที่ได้เรียนรู้ จากการค้นหาแล้วแก้ไขปัญหาของ Express.js ดังนี้
1. ก่อนจะนำ library หรือ dependency ต่างๆ มาใช้งานนั้น จำเป็นต้องเข้าใจมันอย่างดีก่อนเสมอ
เพื่อให้รู้ว่า เราใช้งานมันผิด หรือ ตัวมันเองที่ทำงานไม่ถูกต้อง
2. ปัญหาเรื่อง perfomance นั้น จำเป็นต้องมีเครื่องมือ หรือ วิธีการช่วยตรวจสอบเสมอ
ตัวอย่างเช่น Flame graph มันช่วยให้เราเห็นการใช้งาน CPU ของระบบงานของเราอย่างละเอียด
ลองคิดดูเล่นๆ ว่า ถ้าไม่มีเครื่องมือแบบนี้ เราจะหา root cause และแก้ไขปัญหานี้ได้อย่างไร
จากปัญหาที่พบทำให้ทีมพัฒนาเปลี่ยนไปใช้ Restify
เนื่องจากทีมพัฒนาเห็นว่า มันสามารถดูการทำงานภายในได้ง่ายและชัดเจน
ตลอดจนสามารถควบคุมระบบงานได้ดีกว่า …





