วันนี้ว่าง ๆ เลยมานั่งอ่าน The InfoQ eMag – Taming Complex Systems in Production
เป็น miniBook จากทาง InfoQ
แนะนำสำหรับจัดการหรือควบคุมระบบงาน
ที่ยิ่งนานวันยิ่งมีความซับซ้อนมากขึ้นเรื่อย ๆ
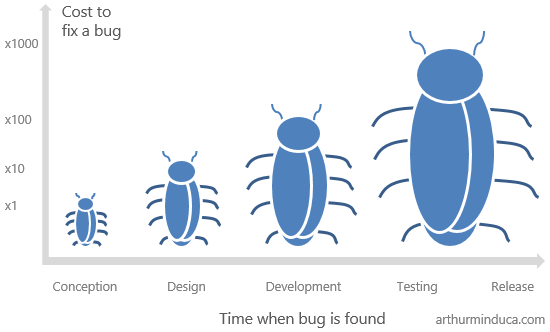
ยิ่งเมื่อเกิดปัญหาขึ้นมา บ่อยครั้งต้องมีค่าใช้จ่ายสูงมากในการแก้ไข
เพื่อให้ระบบกลับมาทำงานได้อย่างปกติ
ดังนี้เราควรต้องทำการแก้ไขและปรับปรุงแล้วนะ
ก่อนอื่นเราต้องทำการปรับปรุงในแง่ขององค์กร คน และระบบการทำงาน
ให้มีความยืดหยุ่น และสามารถกลับคืนมาสู่สภาวะการทำงานปกติได้ง่าย
โดยเนื้อหาในหนังสือนี้ ประกอบไปด้วยเรื่องย่อย ๆ ดังนี้
- An Engineer’s Guide to a Good Night’s Sleep
- Designing Chaos Experiments, Running Game Days, and Building a Learning Organization
- Sustainable Operations in Complex Systems with Production Excellence
- Unlocking Continuous Testing: The Four Best Practices Necessary for Success
- Testing in Production—Quality Software Faster
ใน blog นี้มาดูเรื่อง An Engineer’s Guide to a Good Night’s Sleep กัน
แค่ชื่อหัวข้อก็โดนใจแล้ว
เพราะเชื่อว่าทุกคนในสายการพัฒนา software ต้องเจอเหตุการณ์
ระบบล่มหรือมีปัญหาในช่วงเวลาพักผ่อนแน่นอน !!
ดังนั้นมาดูกันว่า ในหัวข้อนี้มีการจัดการกันอย่างไรบ้าง ?
ปล. สิ่งที่ตลกร้ายก็คือ
หลาย ๆ องค์กรมักจะมี environment เยอะมาก ๆ
ทั้ง Dev, QA, SIT, SUT, UAT, Staging และ Production
เราจะพบว่าทุก ๆ environment จะทำงานผ่านหมด ทดสอบผ่านหมด
แต่เมื่อทำการ deploy ขึ้น Production แล้วกลับเกิดข้อผิดพลาดขึ้นมา
ลองคิดดูสิว่า มันมีอะไรแปลก ๆ ไหมนะ ?

จากหนังสือแนะนำ 5 วิธีการที่จะช่วยลดการโทรตามให้ทีมเข้ามาช่วยแก้ไขบน Production
มาดูในแต่ละวิธีการว่าเป็นอย่างไร ?
วิธีที่ 1 Enable the engineer
ในการสร้างระบบงานที่ดีนั้น
สิ่งที่ควรมองเป็นหลักคือ เรื่องของ operation
ต้องคิดก่อนทำเสมอว่า operation จะต้องมีอะไรบ้าง
ปัญหาที่อาจจะต้องเกิดขึ้นมีอะไรบ้าง
เก็บข้อมูลอะไร ดูอย่างไร แจ้งอย่างไร แก้ไขอย่างไร ?
ไม่ใช่สักแต่สร้าง แล้วมาดูกันว่าจะ operate มันอย่างไร ?
แบบนี้มีแต่พังกับพัง !!
หลังจาก deploy ต้องมานั่งเฝ้าระบบ แก้ไขระบบเอง
นอนก็ไม่ค่อยจะหลับ เพราะว่าหวาดระแวง !!
ในฝั่ง operation นั้น
ควรนำคนจากฝั่ง engineer ไปวนทำด้วย
เพื่อจะได้ให้เห็นปัญหา และจะได้ช่วยกันปรับปรุงระบบและการทำงาน
มิเช่นนั้น การ operate ก็จะไม่ดีขึ้นเลย
ยิ่งคนทำไปลองรับปัญหาหน้างานด้วย
จะยิ่งเข้าใจว่าต้องทำอะไร เพื่อปรับปรุงให้ดีขึ้น
เรื่องการจัดการ error ก็สำคัญ
ระบบที่ดีควรมีการ alert หรือแจ้งเตือนปัญหาที่เกิดขึ้น
จะให้ดีควรต้องแจ้งก่อนที่จะเกิดปัญหา หรือมีรูปแบบหรือแนวโน้มของปัญหา
ก็ควรต้องแจ้งตั้งแต่เนิ่น ๆ จะได้เตรียมการรับมือได้ทัน
จากนั้นควรจัดกลุ่มของ error ตามระดับความรุนแรงในแต่ละ service ไว้ด้วย
เพราะว่า ไม่ใช่ทุก error ต้องแก้ไขทันที
มิเช่นนั้นจะมีแต่ระดับความรุนแรงสูงหมด
เพราะว่าอยู่บน production ซึ่งไม่ใช่เรื่องที่ถูกต้องเลย
เพราะว่า งานบางอย่างทำการแก้ไขในเวลาปกติได้ ไม่ต้องแก้ไขทันที
จำไว้ว่า ระบบจะซับซ้อนขึ้นเรื่อย ๆ ถ้าเราไม่สนใจงานของการ operation ตั้งแต่แรก
เพื่อลดงานต่าง ๆ ลงไป
และจะยิ่งทำให้คุณภาพของระบบงานแย่ลงไปอีกด้วย
ยิ่งถ้าใครบอกว่า เราพยายามแยกเป็น service ย่อย ๆ แล้วนะ
แต่ไม่สนใจ operation ก็ยิ่งพังไปกันใหญ่
ดังนั้นระมัดระวังกันด้วย
วิธีที่ 2 Avoid out-of-hours calls, by catching more in-hours calls
หลีกเลี่ยงการโทรนอกเวลาการทำงาน
แน่นอนว่า หลาย ๆ คนบอกว่า ไม่ได้นะ
เพราะว่าระบบงานต้องทำงานได้ 24*7
ดังนั้นถ้าเกิดข้อผิดพลาดก็ต้องแก้ไขทันที !!
ประเด็นหลัก ๆ ของวิธีการนี้คือ
เราจะลดจำนวนการโทรตามนอกเวลาได้อย่างไร
นั่นน่าจะเป็นเป้าหมายหลัก ๆ ที่เราทุกคนชอบ มิใช่หรือ ?
แล้วจะลดอย่างไรกัน ?
ปรับปรุงกระบวนการ Release
เป็นไปได้ยากมากที่ในแต่ละครั้งที่เรา release ระบบงานไปนั้นจะไม่มีข้อผิดพลาด
ดังนั้นทุก ๆ release หรือ ทุก ๆ การเปลี่ยนแปลงนั้น
ก่อให้เกิดความเสี่ยงต่อการโทรมาหาเราแน่นอน !!
แต่ลองคิดอีกมุมคือ
กว่าเราจะรู้ว่ามีข้อผิดพลาด ต้องใช้เวลานานเท่าไร ?
เป็นนาที ชั่วโมง วัน สัปดาห์ หรือเดือน ?
อีกประเด็นคือ เราจะลดความเสี่ยงนี้ไปได้อย่างไร ? ไม่ต้อง release เลยดีไหม ?
ระบบงานใดก็ตามที่กลัวการ release มาก ๆ
นั่นเป็นอาการของความไม่เชื่อมันต่อคนและระบบ
คำถามคือ เราไม่ทำการแก้ไขปัญหาเหล่านี้กันหรือไง ?
ถ้าการ release มันใหญ่ ก็ลดขนาดให้เล็กลง
ถ้าการ release ต้องมีงาน manual เยอะ ก็ปรับเปลี่ยนไปเป็น automated มากขึ้นไหม
ถ้าระบบต่าง ๆ ชอบมีปัญหาบ่อย ๆ
ดังนั้นควรต้องมีวิธีการทดสอบบน production ก่อนที่จะ release ไหม
หรือว่าควรมีวิธีการเปิดหรือปิด feature ต่าง ๆ กันไหม
เพื่อช่วยเพิ่มความมั่นใจในการจัดการ
หรือว่ามีวิธีการ replay request ที่ก่อให้เกิดปัญหาได้หรือไม่
สิ่งต่าง ๆ เหล่านี้คือ คำถามที่เราควรหาวิธีการเพื่อตอบให้ได้
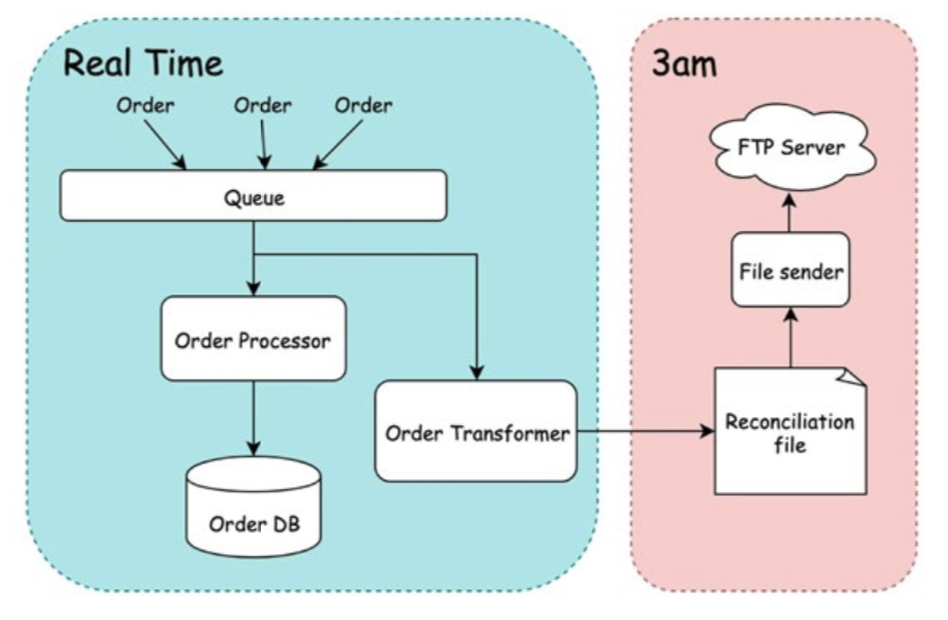
ลดการทำงาน Batch job ลงไป
ให้เหลือเฉพาะงานที่จำเป็นจริง ๆ
งานอะไรที่ทำแบบ realtime ได้ ก็ปรับไปซะ
ยกตัวอย่างเช่น
ในทุก ๆ คืนจะต้องทำการ transform ข้อมูลขนาดใหญ่
เพื่อโยนข้อมูลไปให้อีกระบบหนึ่งทำงาน
เช่นการทำ reconcile เป็นต้น
ดังนั้นแทนที่จะทำการ transform ข้อมูลเป็น batch job
ก็แปลงมาเป็นแบบ realtime ซะเลย
ส่วนขั้นตอนการ reconcile ก็เป็น batch job ไป
วิธีที่ 3 Automate failure recovery wherever possible
ถ้าอะไรที่ให้ computer หรือ machine ทำให้ได้ ก็จัดการซะ
จะได้ไม่ต้องตื่นมาทำเอง มันเสียทั้งเวลา สุขภาพและจิตใจ
นั่นคือ พยายามให้งานเป็นแบบ autoimated มากที่สุด
วิธีการนี้ก็เช่นกัน
ถ้ามีข้อผิดพลาดขึ้นมาแล้ว ระบบงานน่าจะ recover ได้ด้วยตัวเองให้ได้มากที่สุด
ยกตัวอย่างเช่น
ในการใช้งาน Kubernetes นั้น ถ้ามีบาง Pod มีปัญหา
อาจจะต้องสร้าง Pod ใหม่หรือ restart แบบอัตโนมัติให้
ไม่ใช่ต้องให้เราตื่นมากทำเอง
แต่สิ่งสำคัญคือ ระบบงานก็ต้องสนับสนุนวิธีการเหล่านี้ด้วยเช่นกัน
มิเช่นนั้น ก็อาจทำให้เกิดความเสียหายขึ้นมาได้
ยกตัวอย่างเช่น
- Graceful shutdown/terminate
- การจัดการ transaction
- Clean restart
- การจัดการเรื่องของ queue
- การทำงานต้องมีคุณสมบัติ Idempotency
- Stateless
อีกสิ่งหนึ่งที่ต้องเข้าใจคือ ระบบพังได้เสมอ
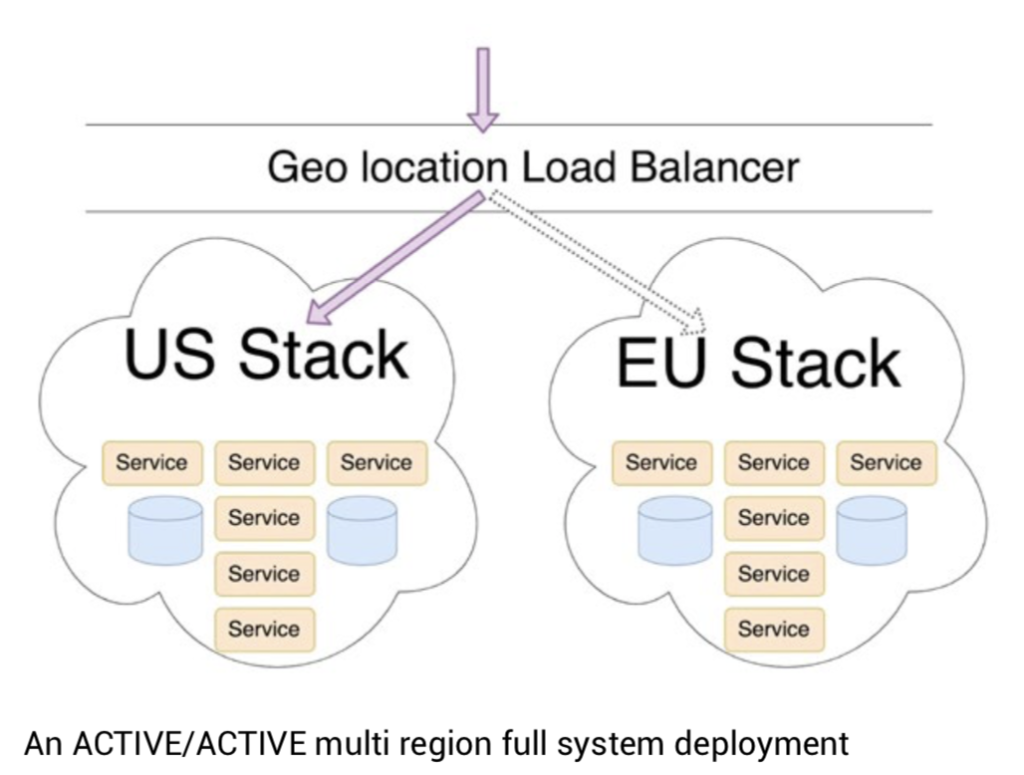
ดังนั้นโครงสร้างของระบบงานต้องมีระบบสำรองเสมอ
เช่นการทำงานแบบ Active-Active และ Active-Standby เป็นต้น
วิธีที่ 4 Understand what your customers care about
วิธีที่ 5 Break things and practice
ไว้มาเขียนต่อ มันยาวเกินไปแล้ว !!!