ทางทีมพัฒนาของ Pinterest ได้เขียนบทความอธิบายการสร้างระบบ Analytic ของตัวเอง
เอาไว้ที่ Building Pinalytics: Pinterest’s data analytics engine
มาดูว่าเขาสร้างระบบนี้อย่างไร
และมีอะไรที่น่าสนใจบ้าง
จุดเริ่มต้น
ที่ Pinterest นั้นเป็นบริษัทที่ใช้ข้อมูลจากผู้ใช้งานระบบ
มาทำการวิเคราะห์เพื่อสร้าง feature ใหม่ขึ้นมา
เพื่อที่จะได้สร้าง feature ที่มีคุณค่าต่อผู้ใช้งานมากที่สุด
ยิ่งในบริษัทของ Pinterest เองด้วยแล้ว มีคำถามว่า
เราจะรู้ข้อมูลต่างๆ ในระบบรวดเร็วได้อย่างไร ?
เราจะรู้และเข้าใจในข้อมูลเหล่านั้นแบบง่ายๆ ได้อย่างไร ?
ดังนั้นทีมพัฒนาจึงสร้างระบบ Pinalytics
ซึ่งเป็นระบบ Analytic ของตัวเองขึ้นมา สำหรับวิเคราะห์ข้อมูลของตัวเอง
ที่เรียกได้ว่าเป็น Big data
เป้าหมายของการสร้าง Pinalytics
ระบบต้องมีหน้าตาการใช้งานที่เรียบง่าย
สำหรับการสร้าง custom dasdboard เพื่อวิเคราะห์และแบ่งปันข้อมูล
ระบบการทำงานในฝั่ง backend ต้องสามารถรองรับการขยายตัวได้
โดยมีค่า latency ต่ำๆ ด้วย
และรองรับการเปลี่ยนแปลงข้อมูลแบบอัตโนมัติ
ซึ่งหมายข้อมูลในรายงานต่างๆ จะเปลี่ยนแปลงไปตามข้อมูลได้เอง
และสุดท้ายระบบต้องสามารถแบ่งแยกข้อมูล และ รวมข้อมูล ในหลายมุมมองได้
สถาปัตยกรรมของ Pinalytics
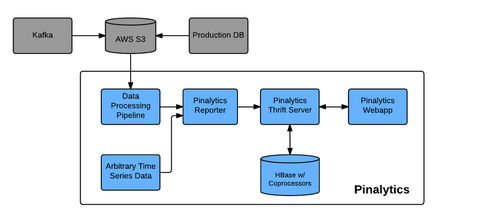
มีส่วนการทำงานหลัก 3 ส่วนคือ
- Web application คือส่วนการแสดงผลเพื่อติดต่อกับผู้ใช้งาน (User Interface)
- Reporter คือส่วนการสร้างรายงานในรูปแบบต่างๆ
- Backend คือส่วนที่ใช้เก็บข้อมูล และ ประมวลผลข้อมูล ซึ่งประกอบไปด้วย Thrift service และ Hbase
มาดูส่วนของ User Interface
ในส่วนนี้ถูกสร้างด้วย Flask framework + MySQL และ SQLAlchemy นี่มัน Python นะเนี่ย
และส่วนของ Frontend พัฒนาด้วย React.js เพื่อสร้าง UI component ต่างๆ
การ Customize ส่วนการแสดงผลรายงานต่างๆ
หัวใจหลักสำหรับระบบนี้ คือ Visualization
โดยข้อมูลจะถูกแสดงแบบ time-series ซึ่งจะทำการเปลี่ยนแปลงในทุกๆ วัน
และแน่นอนว่าส่วนการแสดงผลในรูปแบบต่างๆ ผู้ใช้งานสามารถ customize ได้เอง
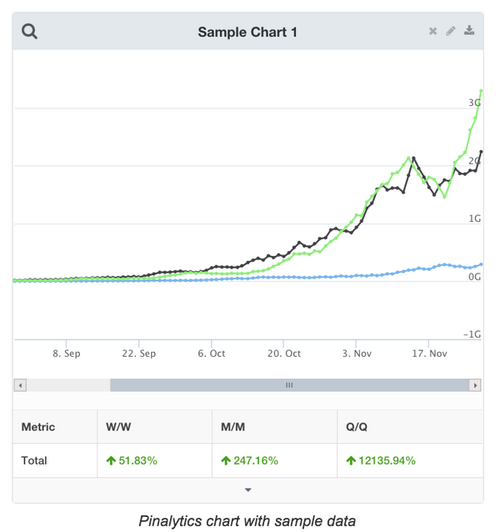
ในบทความบอกว่า ทาง Pinterest มี dashboard มากกว่า 100 dasdboard
เพื่อใช้ในการ moniotring ข้อมูล และ ช่วยสรุปผลในแต่ละวัน
ตัวอย่างดังรูป
อีกทั้งยังสามารถทำการใส่ function การทำงานต่างๆ ไปได้ตั้งแต่หน้า frontend กันเลย
มันเหมือนเป็นการใส่สูตรต่างๆ เพื่อแสดงผลตามที่ต้องการ
ตัวอย่างเช่น DIVIDE(SUM(M1, M2), M3)
ทำให้ระบบมีความยึดหยุ่งต่อการใช้งานมากยิ่งขึ้น
นี่มันระบบ Spraedsheet บน web ชัดๆ
เรื่อง Metric computation
เนื่องจากทางผู้ใช้งาน หรือ พนักงานนั้นสามารถสร้าง job หรือ report ขึ้นมาได้เอง
ดังนั้นมันอาจจะก่อนให้เกิดการทำงานเดิมๆ ซ้ำๆ บนข้อมูลชุดเดิมๆ
ซึ่งไม่ใช่เรื่องที่ดีมากนัก
ดังนั้นทางทีมพัฒนา จึงได้สร้าง common metric ขึ้นมา
โดยในส่วนนี้จะมีข้อมูลในมิติที่สำคัญๆ ต่อระบบงาน เช่น
- เพศ
- ประเทศ
- ชนิดของ application ต่างๆ
และจะมีส่วนรายงานต่างๆ ที่สำคัญไว้ให้ เช่น
- User activity
- Event ต่างๆ ที่เกิดขึ้น
- Retention
- Signup
ส่วนที่สำคัญมากๆ คือ Backend ที่ต้องรองรับการขยายตัวของระบบ
ความท้าทายของระบบนี้ก็คือ จะรองรับการประมวลผลข้อมูลที่มีอยู่มากมายได้อย่างไร
เนื่องจากผู้ใช้งานสามารถทำการ custom ส่วนต่างๆ ได้หมดเลย
รวมทั้งข้อมูลก็มีหลากหลายมิติอีกต่างหาก
ตัวอย่างเช่น
ถ้าในรายงานหนึ่งๆ ต้องการแบ่งข้อมูลตาม ประเทศ ชนิดของ application และ event ต่างๆ
โดยข้อมูลจะต้องแยกเป็นรายวัน พบว่าข้อมูลที่ต้องดึงขึ้นมาในการประมวลผลครั้งนี้ คือ 1 พันล้าน record !!!
จะทำอย่างไรดีล่ะ ? ปัญหาจึงเกิดสิครับพี่น้อง
ดังนั้น เพื่อลดการดึงข้อมูล และ ลด latency time ในการประมวลผล
จึงต้องการระบบ Backend ที่สามารถรองรับได้นั่นเอง
แล้วทำอย่างไรล่ะ ?
ทางทีมพัฒนาทำการแก้ไขปัญหานี้ด้วยการ
แยก component ของ backend ออกมา
โดยแต่ละ component จะมี Thrift server เพื่อติดต่อสื่อสาร
และมีส่วนการประมวลผลซึ่งใช้ Hbase
รวมทั้งมีสิ่งที่เรียกว่า Secondary Index Table
ใช้เก็บข้อมูล metadata ของทุกๆ รายงาน เช่น metric, ชนิดข้อมูลที่ใช้ในการ segment เป็นต้น
ทำให้เมื่อทำการสร้างรายงานขึ้นมา
ทาง Thrift server จะสั่งให้ Hbase ให้สร้างตารางของรายงาน
และจะทำการสร้าง Secondary Index Table ของรายงานนั้นๆ ขึ้นมา
โดยข้อมูลของแต่ละแถวในตารางเป็นดังรูป

ทำให้ตอนนี้ระบบสามารถทำงานแบบขนานได้อย่างมีประสิทธิภาพ
ส่วนเรื่องของข้อมูลนั้น
ถ้าจะทำการประมวลผลบนข้อมูลทั้งหมดในทุกๆ ครั้งคงจะไม่ไหว
เพราะว่าต้องใช้ทรัพยากรอย่างมากมาย เนื่องจากข้อมูลมีเยอะเหลือเกิน
ดังนั้น ทางทีมพัฒนาจึงได้ทำการแบ่งข้อมูลด้วยวันที่สร้าง
ถ้าผู้ใช้งานต้องการข้อมูล 28 วัน ทางระบบจะทำการเพิ่มข้อมูลให้แบบวันต่อวัน
แต่การทำแบบนี้จะเป็นการสิ้นแปลงทรัพยากร และ จะขยายระบบได้ยาก
ดังนั้นจึงทำการประมวลผลข้อมูลก่อนด้วย Cascading Job ซึ่งทำให้ทีมพัฒนาสร้างระบบได้ง่ายขึ้น
แล้วจึงนำผลลัพธ์ไปจัดเก็บเพื่อใช้งานในรายงานต่างๆ ต่อไป
ด้วยวิธีการนี้ทำให้ระบบสามารถทำงานได้รวดเร็วขึ้น 20-50 เท่ากันเลยทีเดียว
ปล. ถ้ามีเอกสารเยอะกว่านี้ น่าจะสนุกกว่านี้แน่นอน

ผลที่ได้รับจากระบบนี้คือ
พนักงานมากกว่าครึ่งหนึ่งของ Pinterest ใช้งานระบบนี้เพื่อ monioting, tracking ข้อมูลที่ต้องการในทุกๆ วัน
เพื่อทำให้ตัดสินใจได้อย่างรวดเร็ว ในการปรับปรุงประสบการณ์การใช้งานของผู้ใช้
คนที่ได้รับผลประโยชน์ไปเต็มๆ คือ ผู้ใช้งานระบบ นั่นเอง
ถ้าระบบนี้ออกมาให้คนทั้งไปใช้จริงๆ ก็น่าจะดีไม่น้อยนะ …
แต่ว่าเราก็ใช้ Pinterest Analytic ไปก่อนก็แล้วกัน